
标签数量从 10 万减少到 500 以下:谷歌 AI 如何大幅缩减 LLM 训练数据
内容提要
谷歌研究院推出了一种新方法,通过主动学习显著减少大语言模型微调所需的数据量,最多可减少10,000倍,同时提升模型质量。该方法专注于标注信息量最大的“边界案例”,提高了标签效率和模型适应性,降低了成本,加快了更新速度,并增强了处理敏感内容的能力。
关键要点
-
谷歌研究院推出了一种新方法,通过主动学习显著减少大语言模型微调所需的数据量,最多可减少10,000倍。
-
该方法专注于标注信息量最大的“边界案例”,提高了标签效率和模型适应性。
-
传统微调方法需要大量高质量的带标签数据集,增加了数据管理的成本和复杂性。
-
谷歌的主动学习方法使用LLM扫描庞大的语料库,识别最不确定的案例。
-
人类专家仅注释那些边界上、令人困惑的项目,而不是随机示例。
-
模型经过多轮微调,直到输出与专家判断紧密一致,以Cohen’s Kappa衡量一致性。
-
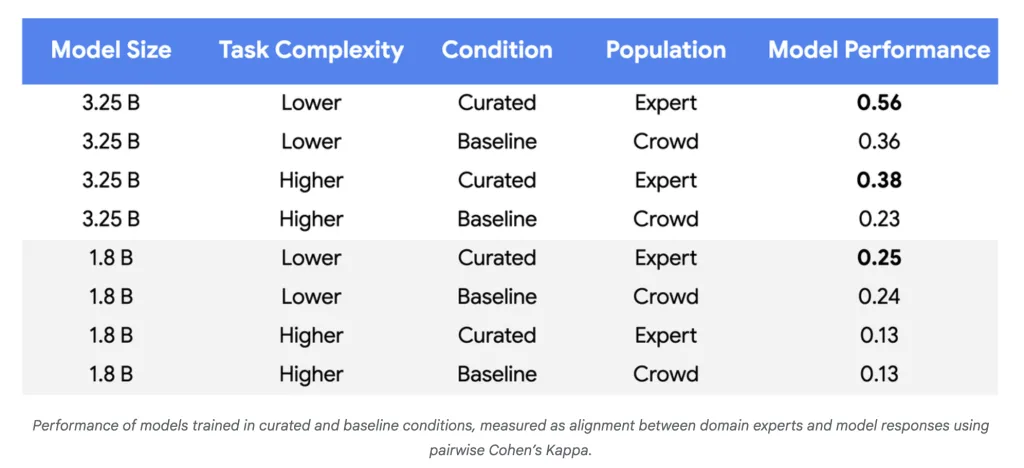
实验表明,使用250-450个精心挑选的示例即可与人类专家的匹配达到同等或更好的效果。
-
对于复杂任务和更大模型,性能改进达到基线的55-65%。
-
高标签质量(Cohen’s Kappa > 0.8)是使用微小数据集获得可靠收益的关键。
-
该方法降低了成本,加快了更新速度,并增强了处理敏感内容的能力。
-
谷歌的新方法使得LLM仅使用数百个高保真标签就可以对复杂任务进行微调。
延伸解读
主动学习的优势
谷歌的新方法通过主动学习显著减少了大语言模型的训练数据需求。这种方法不仅降低了成本,还提高了模型的适应性和更新速度。相比传统方法,主动学习能够更有效地利用有限的标注资源,尤其在处理复杂任务时表现出色。
边界案例的重要性
该方法强调对“边界案例”的标注,这些案例通常是模型最不确定的部分。通过集中精力在这些关键示例上,专家的标注工作变得更加高效,从而提升了模型的整体质量。这种策略使得模型在面对新情况时能够更快适应,减少了重新训练的频率。
高标签质量的关键
在使用少量数据集获得可靠收益的过程中,高标签质量至关重要。Cohen’s Kappa指标的使用确保了标注的一致性,只有当标签质量达到一定标准时,模型才能在复杂任务中表现出色。这提醒我们在数据标注时,质量优于数量。
延伸问答
谷歌的新方法如何减少大语言模型的训练数据量?
谷歌的新方法通过主动学习,将所需的训练数据量减少高达10,000倍,专注于标注信息量最大的“边界案例”。
主动学习在谷歌的研究中起到了什么作用?
主动学习帮助识别最不确定的案例,使人类专家能够集中精力标注最具信息量的示例,从而提高标签效率。
使用谷歌的新方法,微调模型所需的标签数量是多少?
使用250-450个精心挑选的示例即可与人类专家的匹配达到同等或更好的效果。
该方法如何提高模型的质量和适应性?
通过集中标注边界案例并进行多轮微调,该方法提高了模型的质量和适应性,尤其在复杂任务中表现更佳。
谷歌的新方法对成本和更新速度有什么影响?
该方法显著降低了标记示例的数量,从而减少了劳动力和资本支出,同时加快了模型的更新速度。
高标签质量在该方法中有多重要?
高标签质量(Cohen’s Kappa > 0.8)是使用微小数据集获得可靠收益的关键,确保模型输出与专家判断一致。
