
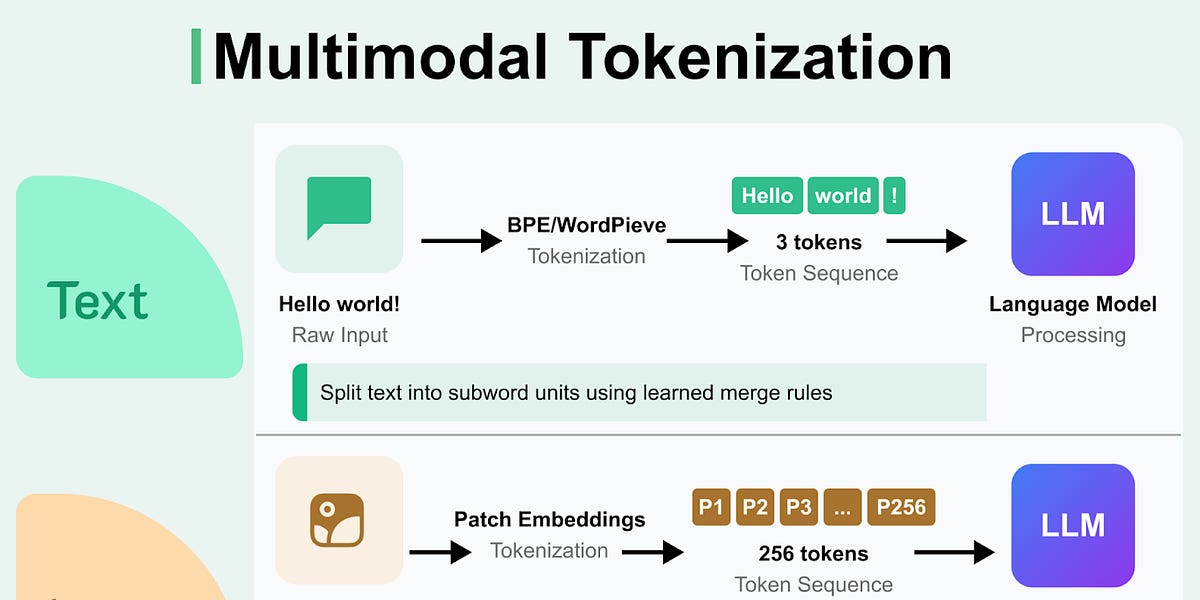
大型语言模型如何理解图像、音频等
ByteByteGo Newsletter
·

大语言模型如何看待世界
ByteByteGo Newsletter
·

标记效率陷阱:零样本与少样本提示的隐性成本
DEV Community
·

什么是LLM标记:开发者入门指南
The New Stack
·

在Rust中构建编译器和解释器!第二部分 Compiler.rs 文件
DEV Community
·
