
大型语言模型如何理解图像、音频等
内容提要
数据流与AI峰会将于2025年9月30日在旧金山举行,汇聚OpenAI、Netflix等行业领袖,探讨多模态标记化及其在图像、音频和视频处理中的策略与优缺点。
关键要点
-
数据流与AI峰会将于2025年9月30日在旧金山举行,汇聚OpenAI、Netflix等行业领袖。
-
会议将探讨多模态标记化及其在图像、音频和视频处理中的策略与优缺点。
-
与会者将听取来自Databricks的Reynold Xin的主题演讲,并参与30多个技术会议。
-
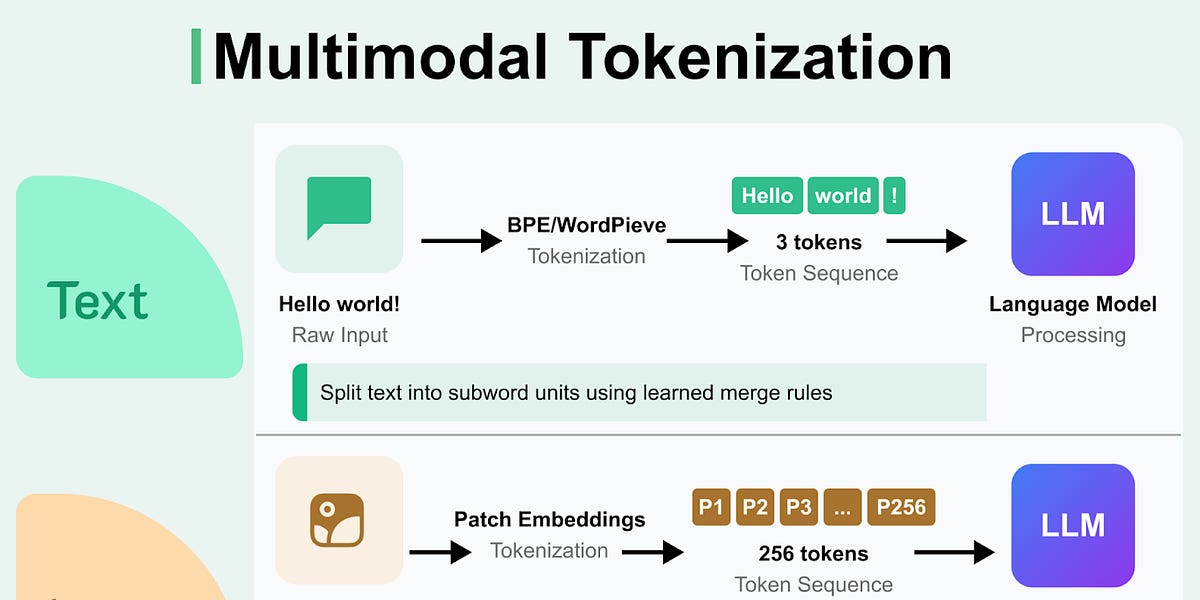
图像标记化将视觉数据转换为可由LLM处理的离散标记,主要方法包括补丁嵌入、离散VAE和对比嵌入。
-
音频标记化将连续音频波形转换为离散标记,主要方法包括神经音频编解码器、语音识别和多尺度标记堆栈。
-
视频标记化通常将视频转化为视频帧,并附加音频进行处理。
-
未来的标记化研究包括无标记化模型和自适应标记化,以提高效率和语义清晰度。
-
每种标记化方法都有其优缺点,直接影响AI系统的理解和生成能力。
延伸解读
多模态标记化的挑战与机遇
多模态标记化是将图像、音频和视频等不同类型的数据转化为可处理的离散标记。每种标记化方法都有其独特的优缺点,影响AI系统的理解能力。了解这些方法的局限性和适用场景,可以帮助开发者选择最合适的技术来满足特定需求。
未来标记化研究的方向
未来的标记化研究可能会集中在无标记化模型和自适应标记化上。这些新方法有望提高处理效率和语义清晰度,尤其是在处理复杂数据时。关注这些前沿研究将有助于把握AI技术发展的趋势。
音频标记化的多样性
音频标记化面临独特挑战,如保持语音的音调和情感。不同的标记化方法(如神经音频编解码器和ASR)在语义和声学信息的保留上存在权衡。开发者需根据具体应用场景选择合适的音频标记化策略,以实现最佳效果。
延伸问答
大型语言模型如何处理图像数据?
大型语言模型通过图像标记化将视觉数据转换为离散标记,主要方法包括补丁嵌入、离散VAE和对比嵌入。
音频标记化的主要方法有哪些?
音频标记化主要包括神经音频编解码器、语音识别和多尺度标记堆栈。
视频标记化是如何进行的?
视频标记化通常将视频转化为视频帧,并附加音频进行处理。
多模态标记化的优势是什么?
多模态标记化允许模型同时处理图像、音频和视频,增强了AI系统的理解和生成能力。
未来的标记化研究方向有哪些?
未来的标记化研究包括无标记化模型和自适应标记化,以提高效率和语义清晰度。
不同标记化方法的主要权衡是什么?
不同标记化方法在信息保留与压缩、计算效率和语义理解之间存在权衡。
