


新技术使人工智能模型在学习过程中更加精简和快速
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·



演讲:大规模生成AI:它的应用、成本及如何减轻负担
InfoQ
·
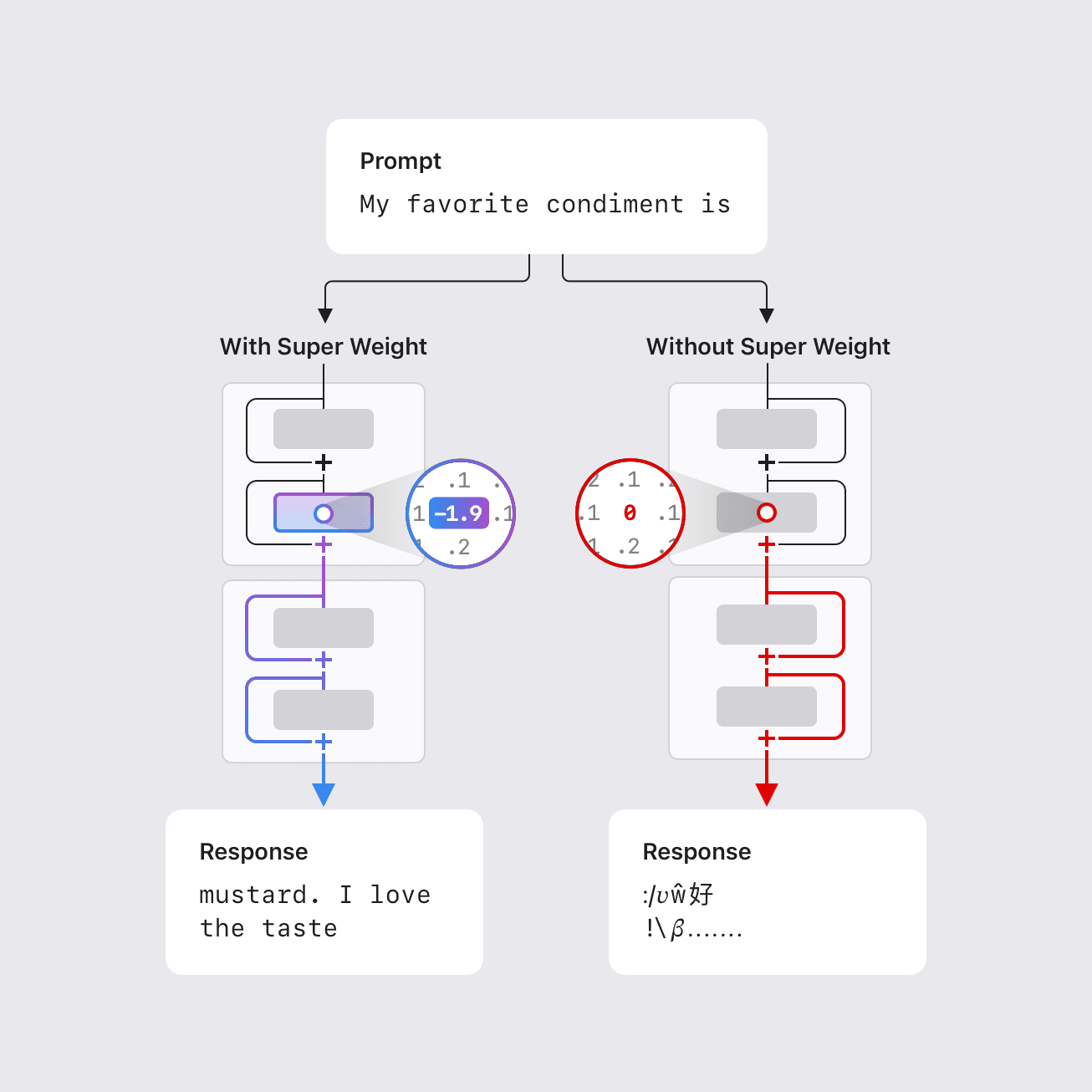
“超级权重”:单个参数如何决定大型语言模型的行为
Apple Machine Learning Research
·

关于信息几何与模型压缩中的迭代优化:操作因子分解
Apple Machine Learning Research
·

Pruna AI的AI效率框架现已开源
DEV Community
·
