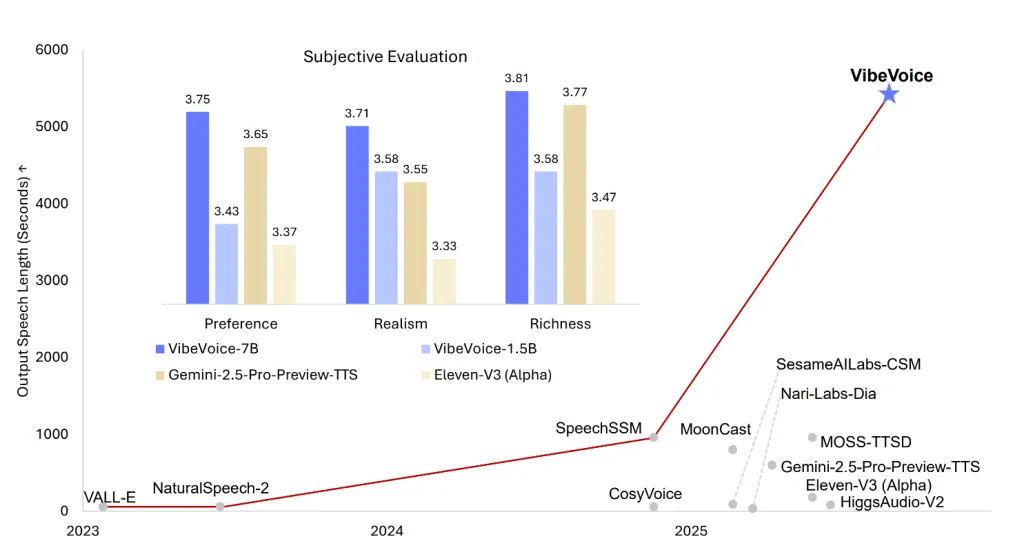
微软的VibeVoice-1.5B是开源文本转语音技术的重大进展,支持长达90分钟的多说话人音频生成,具备跨语言和歌唱合成能力,采用流式架构,强调情感表现,适合播客和对话场景。
本文介绍了基于扩散概率模型的声学模型DiffSinger,提升了歌唱合成的稳定性和生成能力。同时,研究探讨了声音DeepFake检测,提出使用Whisper模型提高检测准确性,并创建了包含真实和伪造歌曲的SingFake数据集,以评估深度伪造检测的挑战与进展。
完成下面两步后,将自动完成登录并继续当前操作。