
VibeVoice-1.5B:微软开源文本转语音模型,可合成四个不同说话者长达 90 分钟的语音
内容提要
微软的VibeVoice-1.5B是开源文本转语音技术的重大进展,支持长达90分钟的多说话人音频生成,具备跨语言和歌唱合成能力,采用流式架构,强调情感表现,适合播客和对话场景。
关键要点
-
微软的VibeVoice-1.5B是开源文本转语音技术的重大进展。
-
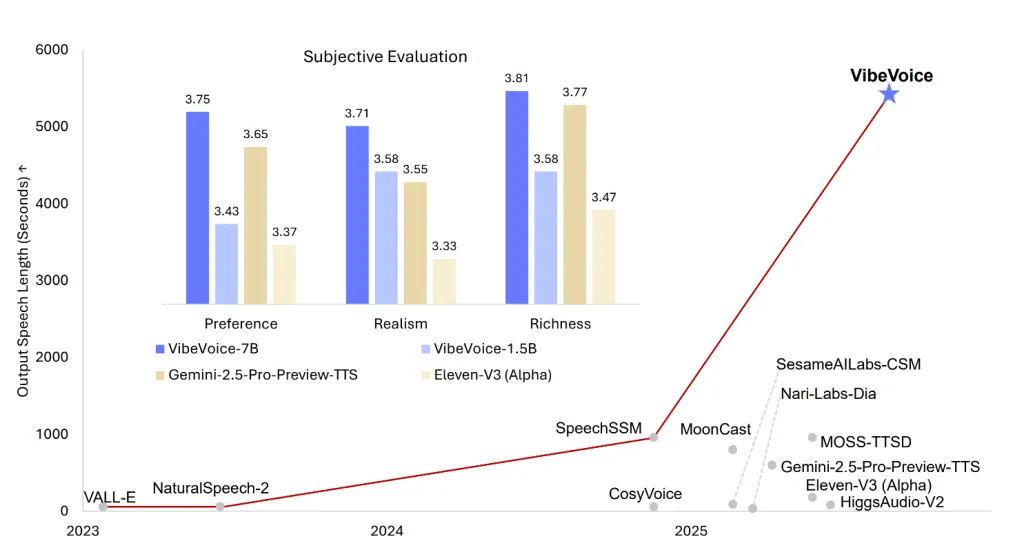
支持长达90分钟的多说话人音频生成,最多可同时生成四个不同的说话人。
-
具备跨语言和歌唱合成能力,主要针对英语和中文进行训练。
-
采用流式架构,强调情感表现,适合播客和对话场景。
-
完全开源且商业友好,专注于研究、透明度和可重复性。
-
模型的基础是一个1.5B参数的LLM,集成了声学和语义标记器。
-
支持长时间合成,预计将推出更强大的7B模型。
-
模型限制在英语和中文,且不支持重叠语音。
-
微软禁止将其用于语音模仿、虚假信息或身份验证绕过。
-
VibeVoice-1.5B是下一代合成语音应用的必备工具,已在Hugging Face和GitHub上发布。
延伸解读
多说话人合成的应用前景
VibeVoice-1.5B支持同时生成多达四个说话人的音频,这一特性使其在播客、对话系统等场景中具有广泛应用潜力。与传统TTS模型相比,它能够更自然地模拟人类对话,提升用户体验。
法律与道德风险的关注
微软明确禁止将VibeVoice-1.5B用于语音模仿和虚假信息传播等用途。用户在使用时需遵循法律法规,确保透明度,以避免潜在的法律和道德风险。
技术限制与未来发展
尽管VibeVoice-1.5B在多说话人合成和情感表现上表现出色,但目前仅支持英语和中文,且不支持重叠语音。未来的7B模型预计将解决这些限制,进一步提升实时交互能力。
延伸问答
VibeVoice-1.5B的主要功能是什么?
VibeVoice-1.5B支持长达90分钟的多说话人音频生成,最多可同时生成四个不同的说话者,具备跨语言和歌唱合成能力。
VibeVoice-1.5B的开源许可证是什么?
VibeVoice-1.5B采用MIT许可证,完全开源且商业友好。
VibeVoice-1.5B适合哪些应用场景?
该模型适合播客、对话场景等需要情感表现的应用。
VibeVoice-1.5B的技术架构有什么特点?
VibeVoice-1.5B采用流式架构,集成了声学和语义标记器,支持高效的长时间合成。
VibeVoice-1.5B的语言支持情况如何?
该模型主要针对英语和中文进行训练,支持跨语言合成,但不支持其他语言。
使用VibeVoice-1.5B需要什么样的硬件?
运行VibeVoice-1.5B建议使用至少8GB的GPU VRAM,例如RTX 3060。
