

大模型启示:泛化是进化能力的一次重大飞跃
极道
·

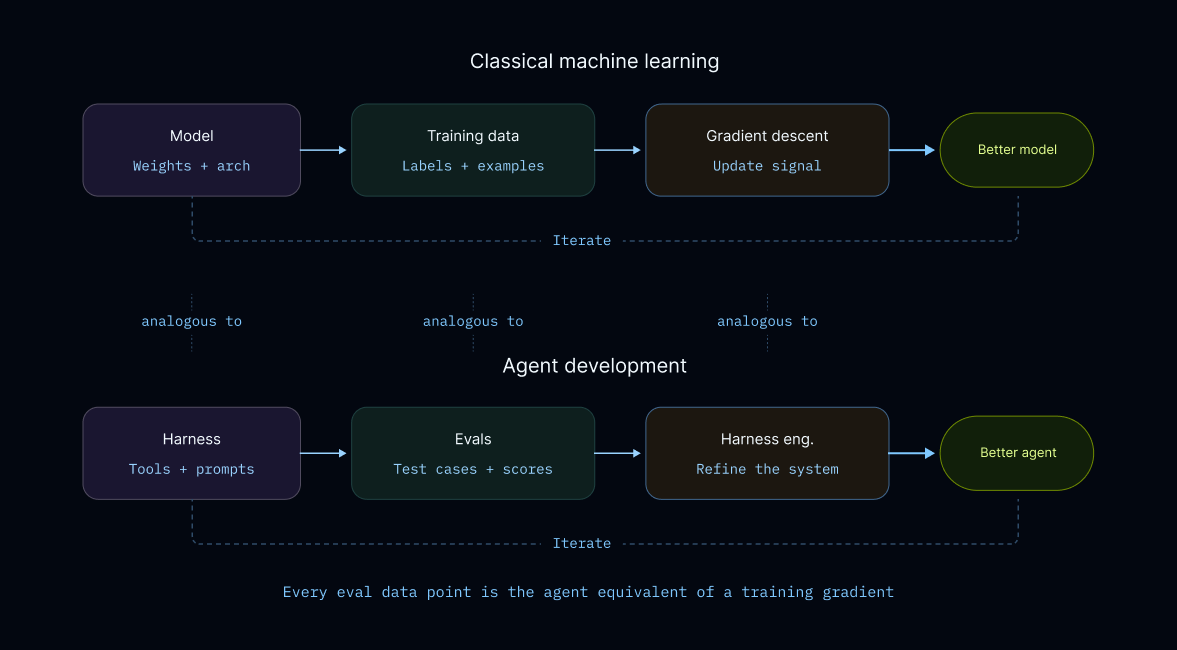
更好的工具:利用评估数据进行工具优化的方案
LangChain Blog
·

超越真实数据:从正则化的视角看合成数据
Apple Machine Learning Research
·

突破传统:ReSU 神经网络单元——从果蝇大脑中获得的 AI 新灵感
Micropaper
·

Agent World Model:1000 个合成环境,让 AI 智能体学习效率翻倍
Micropaper
·

SpecTokenizer:压缩频谱域的轻量级流式编解码器
实时互动网
·

机器学习数据增强完全指南
MachineLearningMastery.com
·


