

在AI时代重新定义数据仓库:Azure Databricks的应用
Databricks
·
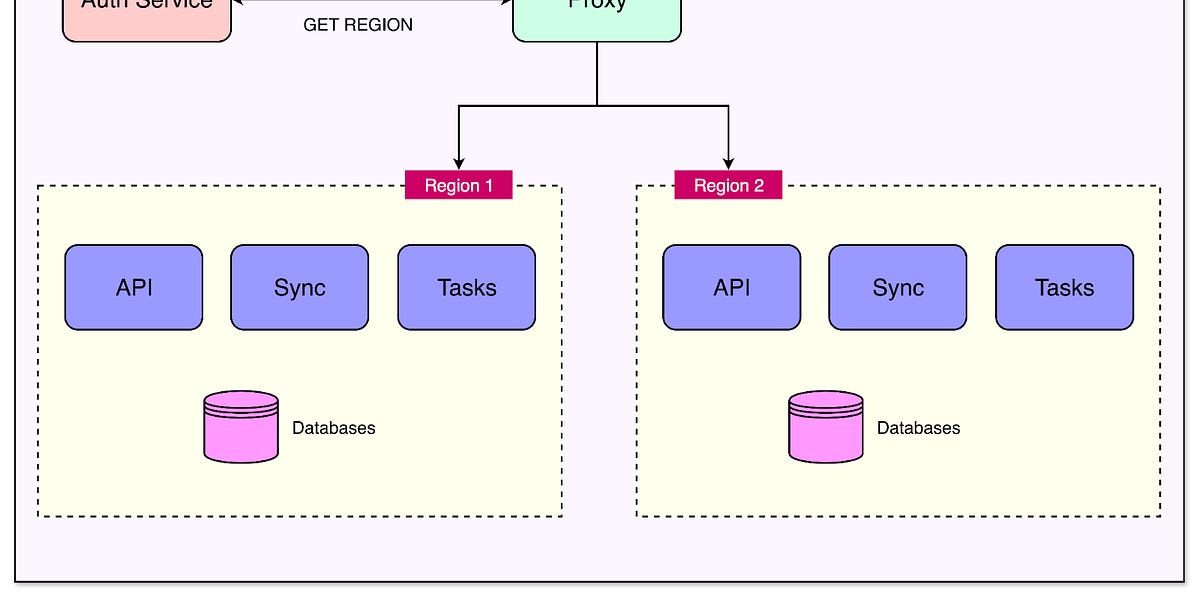
Linear如何为客户实现多区域支持
ByteByteGo Newsletter
·
在线孤立森林
BriefGPT - AI 论文速递
·

在AI时代保障和扩展流数据的五项策略
The New Stack
·


掌握 Node.js 内存:利用 V8 垃圾回收技巧提升应用性能
DEV Community
·

-779w9kev1f.jpg)
Atlas流处理现已正式发布!
MongoDB
·

Atlas Stream Processing 正式发布!
MongoDB
·
Atlas Stream Processing 正式发布!
MongoDB
·
Atlas流处理现已推出!
MongoDB
·
