LLM扩展面临的挑战在于对涌现能力的理解不足。UC伯克利的研究表明,通过微调模型可以预测涌现能力,并发现微调可以提前识别涌现点。研究使用四个NLP基准验证了涌现定律,结果显示微调数据量影响涌现偏移,能够准确预测涌现点。
清华大学和智谱AI团队的研究发现,大模型的涌现能力与预训练损失的关系比模型参数更紧密。解锁涌现能力的关键在于优化预训练损失至关键值以下。
研究人员发现,大规模语言模型的涌现能力是由于衡量指标的选择,而非模型行为的根本性变化。非线性或不连续的衡量标准会导致明显的涌现能力,而线性或连续的度量标准会导致模型性能的平滑、连续、可预测的变化。涌现能力的消失与指标选择相关,不是大规模模型的基本属性。该论文于去年4月底发布,并获得最佳论文奖。
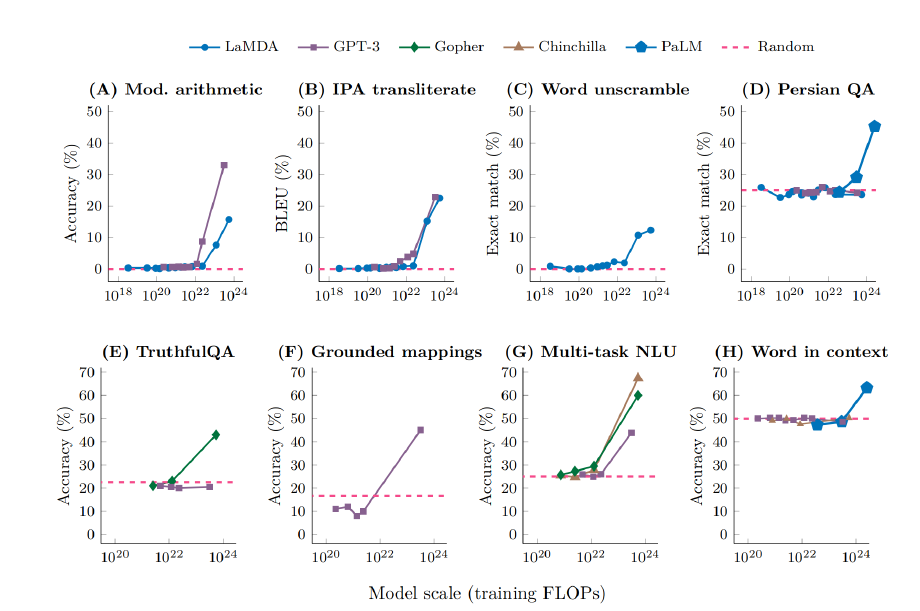
本文介绍了一篇名为《大语言模型的涌现能力》的论文,研究人员对于这些大小不同的语言模型完成了八项新能力的测试。文章探讨了涌现的概念,即模型变得足够大才足够抽象,从而产生从未出现过的全新能力。
本文讨论了大型语言模型的涌现能力,即在大模型中出现但在小模型中不存在的能力。虽然有很多论文讨论了各种各样的涌现能力,但这些能力的不可解释和不可预测性使得一些科技领袖担心这种技术的发展。然而,LLM还不具备人类的心智层面的能力,输出有时对、有时错、有时荒谬,但没有意义。因此,LLM可以用于写会议纪要或者写段代码,但对于文学作品等需要保留每个字的意义的领域,LLM的输出可能不够。
本文介绍了大型语言模型的涌现能力,即“不存在于小模型中但存在于大模型中”的能力。已发现100多个涌现能力的例子,其中少量提示任务的性能对于小模型是随机的,对于大模型是随机的。涌现提示任务专注于特定数据集,而涌现的第二类是小样本提示策略,这是仅适用于足够大规模的语言模型的通用提示策略。
完成下面两步后,将自动完成登录并继续当前操作。