

一分钟读论文:《用扩散语言模型统一多模态理解与生成》
Micropaper
·

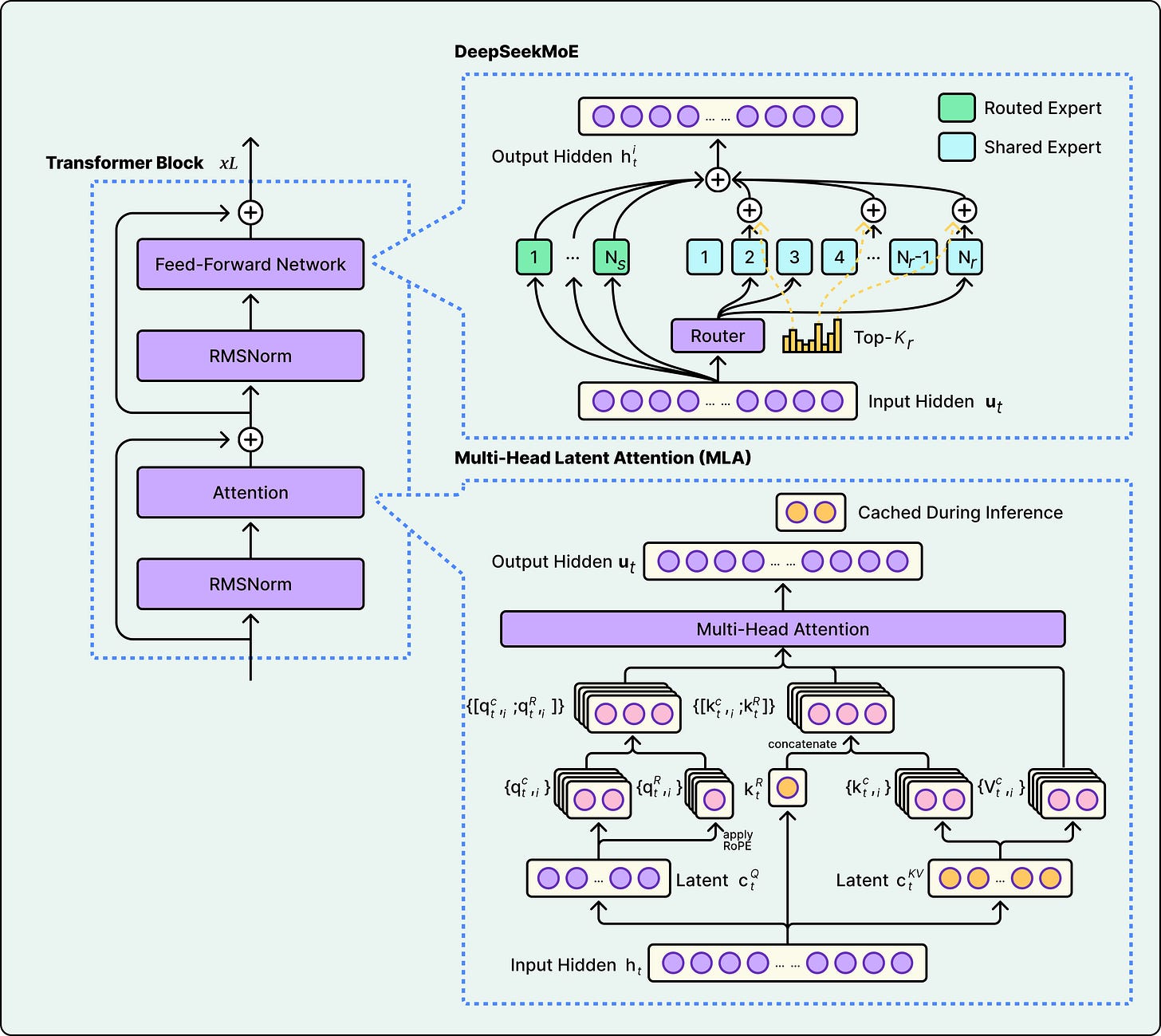
开源大语言模型背后的架构
ByteByteGo Newsletter
·

GLM-4.5发布,具备强大的推理、编码和智能代理能力
InfoQ
·

Qwen 3 基准测试、比较、模型规格及更多信息
DEV Community
·

Seed-Thinking-v1.5:用强化学习推动语言模型的深度推理能力
我爱自然语言处理
·
Kimi-VL:开源多模态模型的新标杆——解读高效视觉语言混合专家模型
我爱自然语言处理
·

Llama 4:解析Meta最新强大模型
DEV Community
·

