
开源大语言模型背后的架构
内容提要
npx workos推出了一款AI代理,能够将身份验证直接集成到现有代码中。DeepSeek V3及其他模型采用混合专家架构,优化了计算效率和内存使用,推动了开源生态的发展。
关键要点
-
npx workos推出了一款AI代理,能够将身份验证直接集成到现有代码中。
-
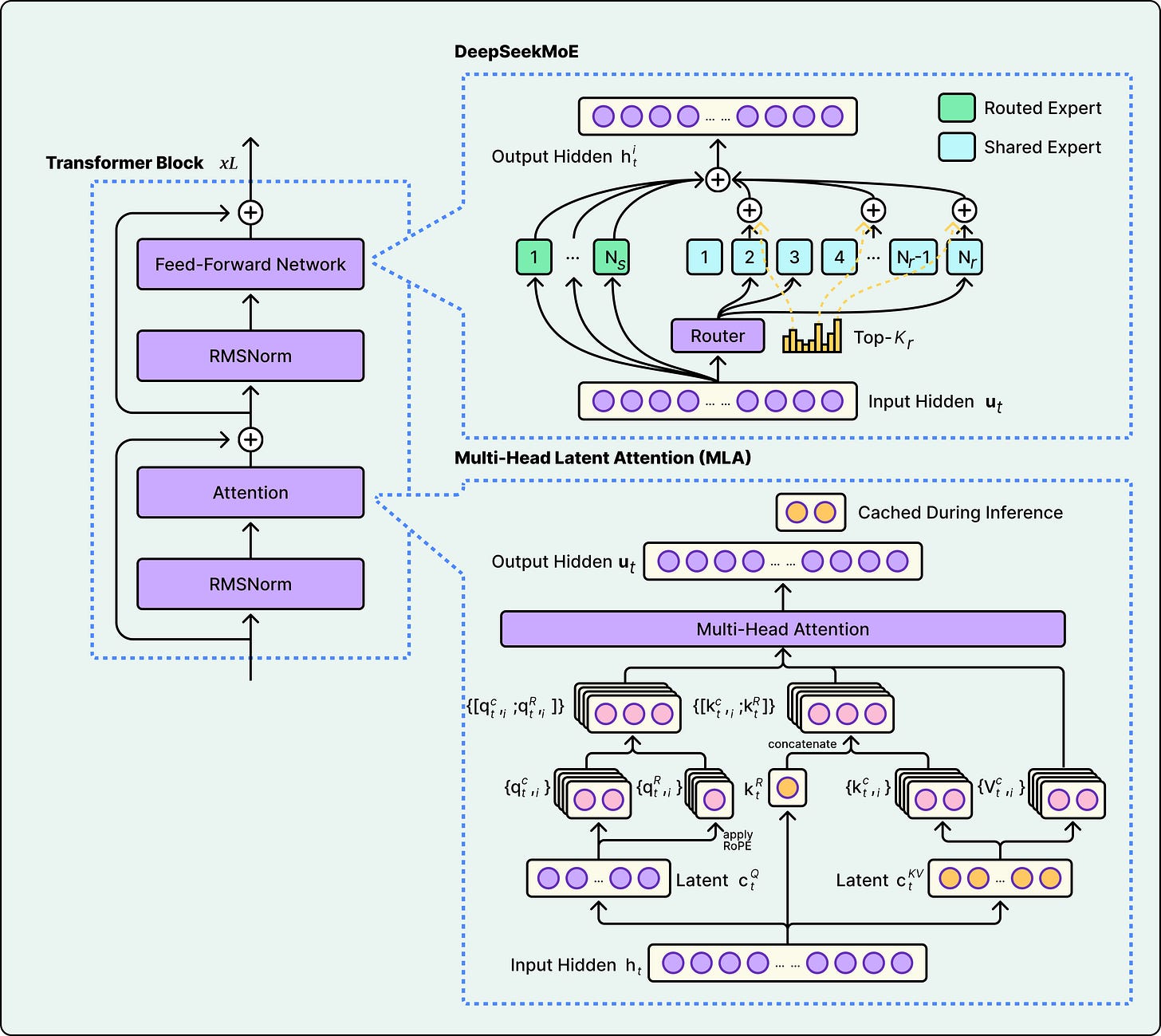
DeepSeek V3采用混合专家架构,优化了计算效率和内存使用。
-
DeepSeek V3的训练成本为557.6万美元,使用了多头潜在注意力机制。
-
混合专家架构通过多个小型专家网络和学习路由器来提高模型效率。
-
每个模型的总参数和活跃参数是评估模型性能的重要指标。
-
几乎所有标榜为“开源”的模型实际上是开放权重,训练数据和完整训练代码通常不可见。
-
不同模型在处理长上下文时采用不同的注意力策略,如分组查询注意力和稀疏注意力。
-
模型的稀疏性设计在训练和验证损失方面存在分歧,增加专家数量可以改善性能,但也增加了基础设施复杂性。
-
训练方法的多样性是模型之间的主要区别,包括强化学习、蒸馏和合成数据。
-
架构趋同,大家都在构建混合专家变换器,但训练方法各有不同。
延伸解读
混合专家架构的优势与挑战
混合专家架构(MoE)通过使用多个小型专家网络来提高计算效率,能够在处理大规模参数时显著降低内存使用。然而,增加专家数量也会带来基础设施的复杂性,尤其是在训练和验证过程中。因此,团队在设计时需权衡性能与复杂性,确保系统能够有效支持所需的计算资源。
开源模型的透明度问题
尽管许多模型被标榜为“开源”,但实际上它们通常只提供开放权重,而训练数据和完整代码却不可见。这种透明度的缺乏可能限制了开发者对模型的理解和改进能力。因此,在选择和使用这些模型时,开发者应关注其许可证和透明度,以便更好地评估其适用性。
注意力机制的选择与应用
不同模型在处理长上下文时采用了不同的注意力策略,如分组查询注意力和稀疏注意力。选择合适的注意力机制不仅影响模型的内存使用,还会影响计算效率和输出质量。开发者在应用时需根据具体需求,评估各策略的优缺点,以优化模型性能。
延伸问答
什么是混合专家架构,它如何优化模型效率?
混合专家架构通过多个小型专家网络和学习路由器来提高模型效率,使得模型在处理时只激活部分参数,从而降低计算成本和内存使用。
DeepSeek V3的训练成本是多少?
DeepSeek V3的训练成本为557.6万美元。
开源模型与开放权重模型有什么区别?
开源模型意味着代码可用、可修改和可再分发,而开放权重模型则是指训练参数公开,但训练数据和完整训练代码通常不可见。
不同模型在处理长上下文时采用了哪些注意力策略?
不同模型使用了分组查询注意力、稀疏注意力和多头潜在注意力等策略来处理长上下文。
训练方法的多样性如何影响模型性能?
训练方法的多样性,包括强化学习、蒸馏和合成数据,是模型之间的主要区别,影响模型的最终性能和应用效果。
模型的稀疏性设计有什么优缺点?
稀疏性设计可以提高模型性能,但增加专家数量也会增加基础设施的复杂性,需权衡计算成本和性能提升。
