本研究提出音频评分蒸馏采样(Audio-SDS),旨在解决音频生成领域缺乏通用模型的问题。Audio-SDS 能够实现多种音频处理任务,如物理音效模拟和源分离,展示了蒸馏方法的广泛适用性。
本研究探讨了室外环境下的基于距离的源分离(DSS),提出了一种结合两阶段conformer block和线性关系感知自注意力(RSA)的模型,显著提高了移动设备的能源效率和实时推断速度。
该研究探讨了多种语音处理模型的优化,包括单声道源分离、语音降噪和超分辨率。提出的模型SPMamba和Wave-U-Mamba在噪声环境中表现优异,处理速度显著提高,实验结果显示其在语音增强和分离任务中效果良好。
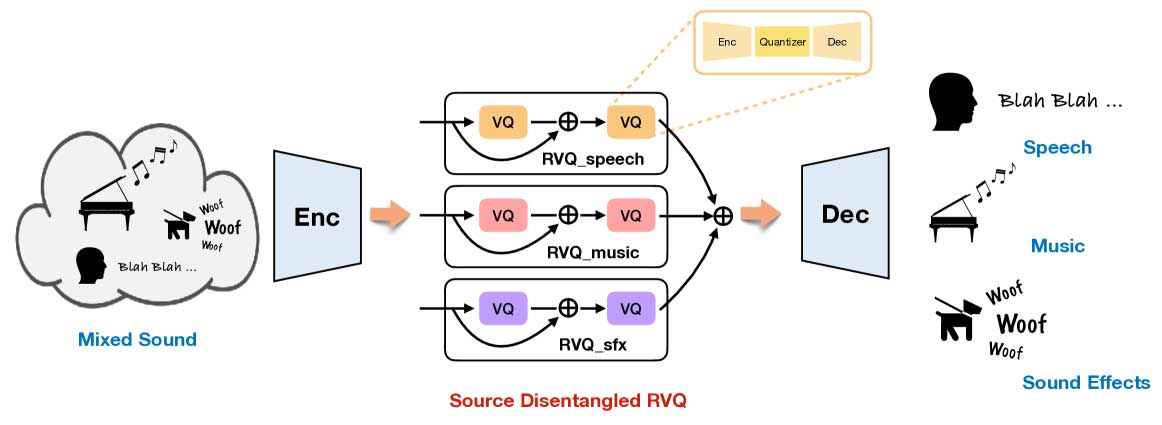
神经音频编解码器通过将音频信号转换为离散标记来提高压缩率,但难以区分音频域。为解决此问题,研究小组推出了SD-Codec,结合源分离和音频编码,提升音频再合成质量。实验显示,SD-Codec在源分离和重建方面表现优异。
本文介绍了一种新的多说话者语音识别框架,采用端到端方式整合源分离和语音识别,实验结果显示相对改进达83.1%。此外,提出了多种语音合成和翻译模型,特别在多人重叠说话和语音到语音翻译任务中表现优越。
ultimatevocalremovergui是一款基于深度神经网络的人声去除工具,支持Windows和MacOS,无需额外依赖。该软件利用先进的源分离模型,能够精准去除音频中的人声。
本文介绍了多种基于掩蔽和深度学习的语音处理方法,包括语音超分辨率、噪声环境下的语音识别提升和单声道源分离。这些方法在不同任务中显著提高了语音表示和识别的性能。
本文探讨了神经网络在模拟神经电路中的应用,研究了啮齿动物和果蝇的头部定向系统,证明神经网络能够自然生成不同类型的神经元。提出了一种新算法以提高脉冲神经网络的训练效率,并展示其在复杂序列学习中的优势,同时提出了一种生物学可行的模型,具备优秀的相关源分离能力。
完成下面两步后,将自动完成登录并继续当前操作。