
Source-Disentangled 神经音频编解码器 (SD-Codec):一种结合音频编码和源分离的新型 AI 方法
原文中文,约1300字,阅读约需4分钟。
📝
内容提要
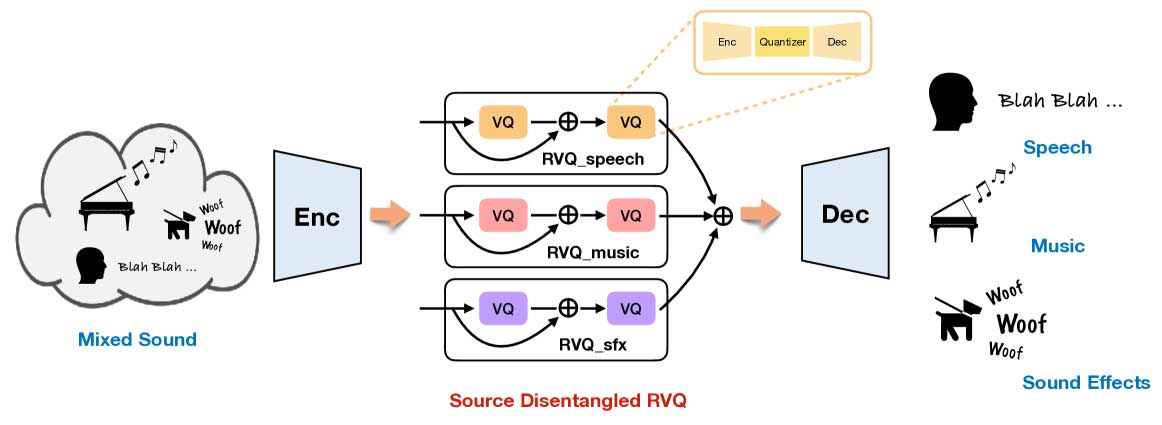
神经音频编解码器通过将音频信号转换为离散标记来提高压缩率,但难以区分音频域。为解决此问题,研究小组推出了SD-Codec,结合源分离和音频编码,提升音频再合成质量。实验显示,SD-Codec在源分离和重建方面表现优异。
🎯
关键要点
-
神经音频编解码器通过将连续音频信号转换为离散标记,提高了音频压缩率。
-
现有的神经音频编解码器难以区分不同的声音域,影响音频处理效果。
-
研究小组推出了SD-Codec,结合源分离和音频编码,提升音频再合成质量。
-
SD-Codec能够识别并分类不同音频信号,改善音频处理的可解释性。
-
SD-Codec在源分离和音频重建方面表现优异,适应性和实用性增强。
-
研究表明,SD-Codec的性能不受通用码本影响,强调了音频输入的分层处理。
-
使用大规模数据集训练的SD-Codec在各种声学情况下表现可靠。
❓
延伸问答
SD-Codec 是什么?
SD-Codec 是一种结合源分离和音频编码的神经音频编解码器,旨在提高音频再合成质量。
SD-Codec 如何提高音频处理的效果?
SD-Codec 通过识别并分类不同音频信号,增强了音频处理的可解释性和控制能力。
SD-Codec 在源分离方面的表现如何?
实验表明,SD-Codec 在源分离和音频重建方面表现优异,能够有效分离各种音频源。
SD-Codec 的训练数据集有什么特点?
SD-Codec 使用大规模数据集进行训练,确保其在各种声学情况下的可靠性和功能性。
SD-Codec 如何处理不同音频域?
SD-Codec 为不同音频源分配离散表示,使其能够更好地识别和保持每种音频形式的独特品质。
SD-Codec 的优势是什么?
SD-Codec 提供了更高的音频压缩率和更好的音频再合成质量,适应性和实用性增强。
🏷️
