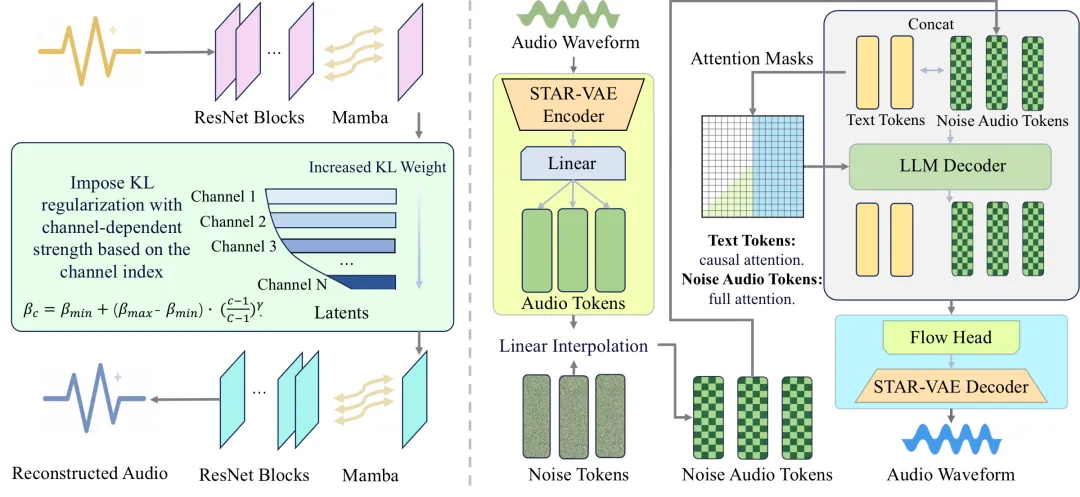
阿里团队的研究STAR-VAE在音频生成领域取得突破,提出了一种新型正则化策略,解决了音频VAE的“率-失真-规整度不可能三角”问题。该方法通过结构化拓扑感知正则化,优化潜在空间,提高了音频重建和文本生成音频的质量,刷新了当前最优结果。
FastDiff是一种快速条件扩散模型,能够实现高质量的语音合成,速度提升至58倍。研究中提出了MQTTS系统和NAST-S2X框架等新算法和模型,显著提高了语音合成的质量和解码速度。同时,WavTokenizer和X-Codec等方法解决了音频压缩和语义完整性问题,提升了音频重建的质量和可懂性。
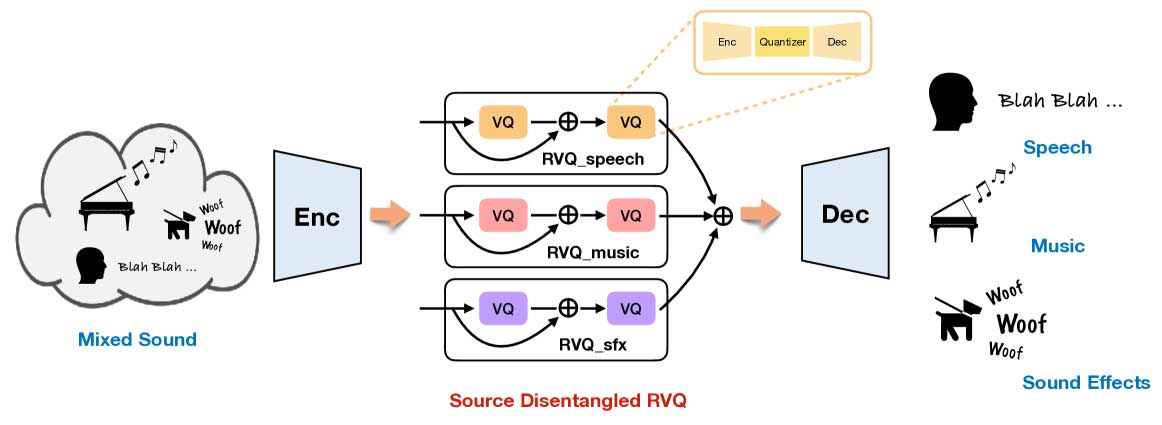
神经音频编解码器通过将音频信号转换为离散标记来提高压缩率,但难以区分音频域。为解决此问题,研究小组推出了SD-Codec,结合源分离和音频编码,提升音频再合成质量。实验显示,SD-Codec在源分离和重建方面表现优异。
本文介绍了多种基于深度学习的音乐生成和分离模型,如最大熵原理、变分自编码器和扩散模型。这些模型能够实现音乐创作、风格转换和高质量音频重建,推动了音乐生成技术的发展。
完成下面两步后,将自动完成登录并继续当前操作。