研究团队创建了Diff-SSL-G-COMP数据集,包含19,500个音频压缩示例,采用创新的数据生成方法,提升了音频压缩建模性能,帮助计算机更好地模拟音频压缩器。
开源音频压缩格式WavPack发布5.8版本,新增多线程支持,提升了编码和解码性能,解决了低比特率和高采样率下的量化噪声问题,并优化了DNS算法。
团结引擎1.4.0发布,优化小游戏性能,增强图形渲染,支持多平台构建,改进音频压缩,推出虚拟阴影贴图,提升开发体验与引擎稳定性。
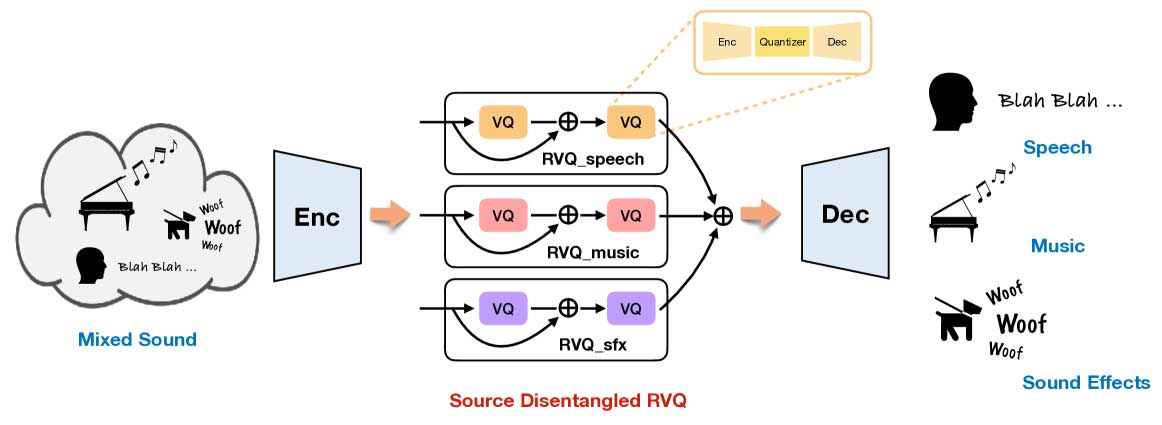
神经音频编解码器通过将音频信号转换为离散标记来提高压缩率,但难以区分音频域。为解决此问题,研究小组推出了SD-Codec,结合源分离和音频编码,提升音频再合成质量。实验显示,SD-Codec在源分离和重建方面表现优异。
本研究提出了一种低帧率语音编解码器(LFSC),旨在提高训练和推理速度。LFSC通过有限标量量化和对抗训练,以1.89 kbps的比特率和21.5帧每秒的速度实现高质量音频压缩,推理速度提高约三倍,同时保持音质和可懂性。
本研究探讨了脉冲神经网络(SNN)的训练方法,提出了多种新算法和框架,提升了音频压缩、视频重建和语音识别等任务的性能,强调了稀疏脉冲编码的优势及其在复杂时间信息处理中的应用潜力。
完成下面两步后,将自动完成登录并继续当前操作。