

S&P Global利用Amazon FSx和NetApp ONTAP快照的创新灾难恢复策略
AWS Architecture Blog
·

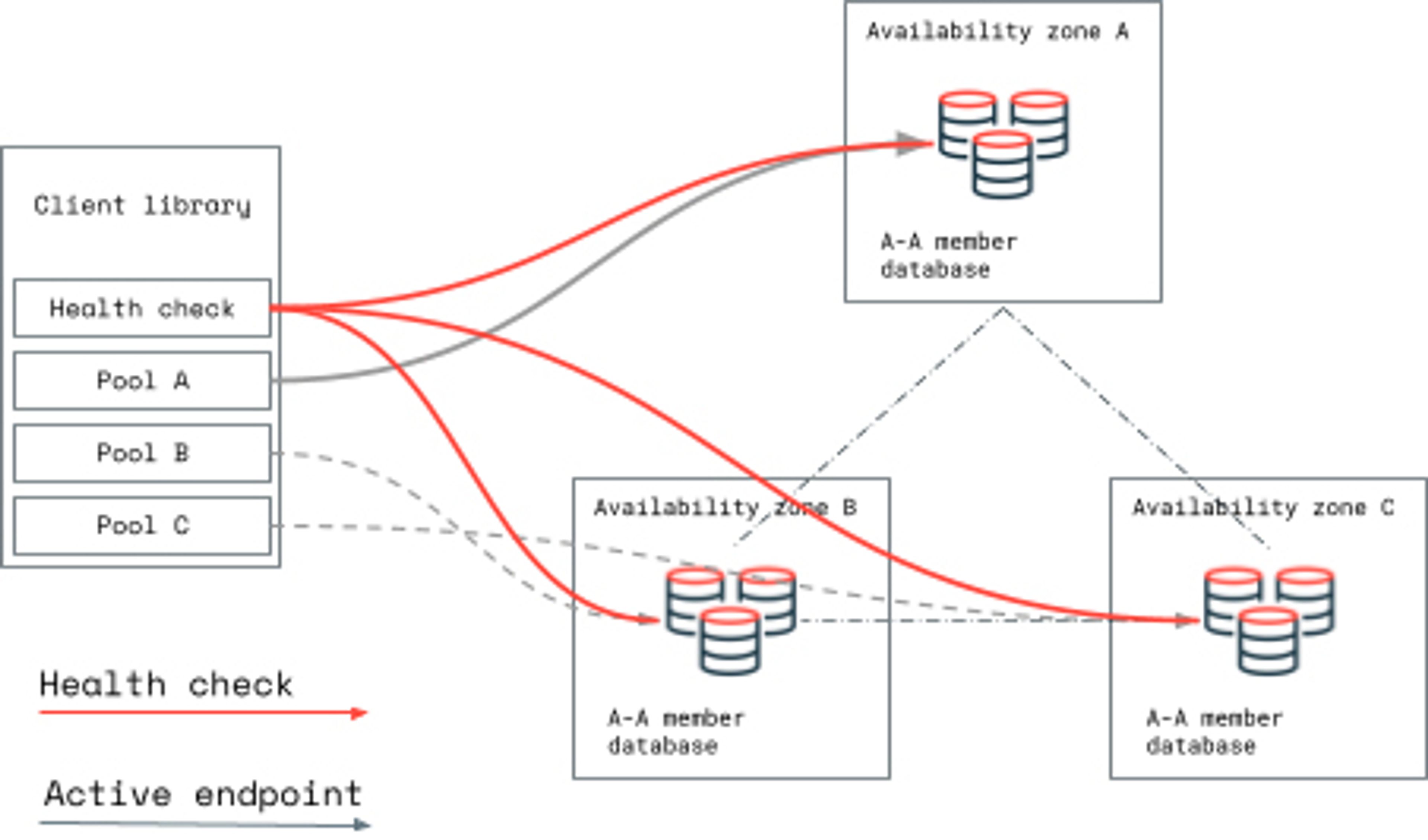
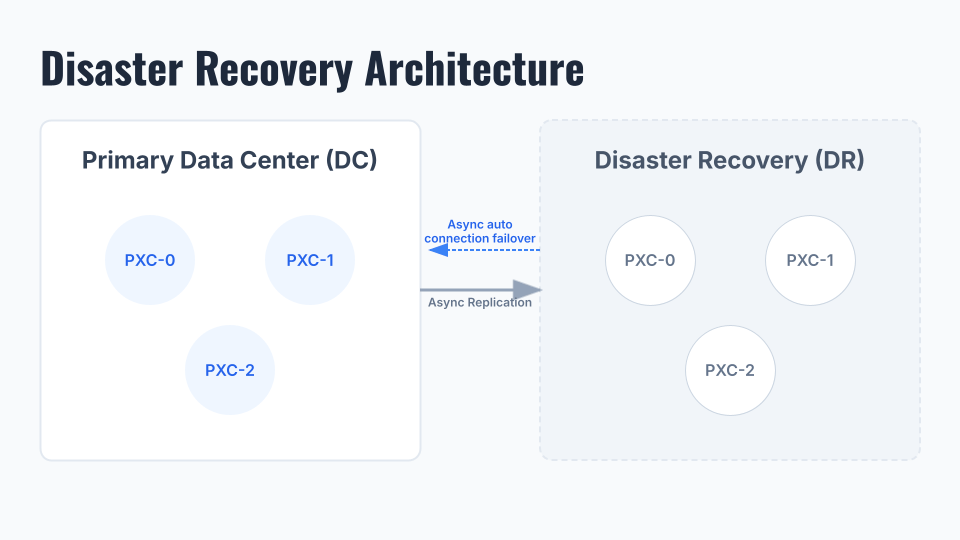
在Percona Operator for MySQL (PXC)中部署跨站点复制
Planet MySQL
·
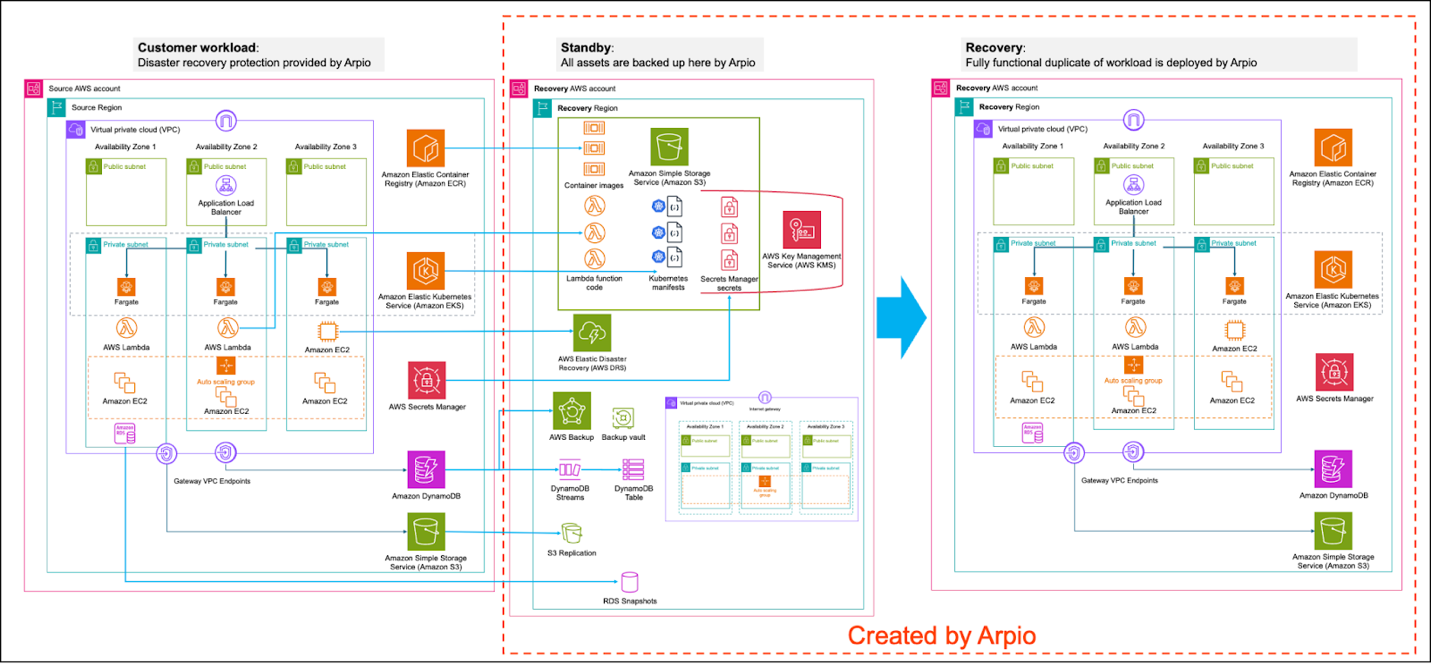
简化访问AWS强大灾难恢复能力
AWS Architecture Blog
·


什么是灾难恢复测试?附实用示例解析
freeCodeCamp.org
·

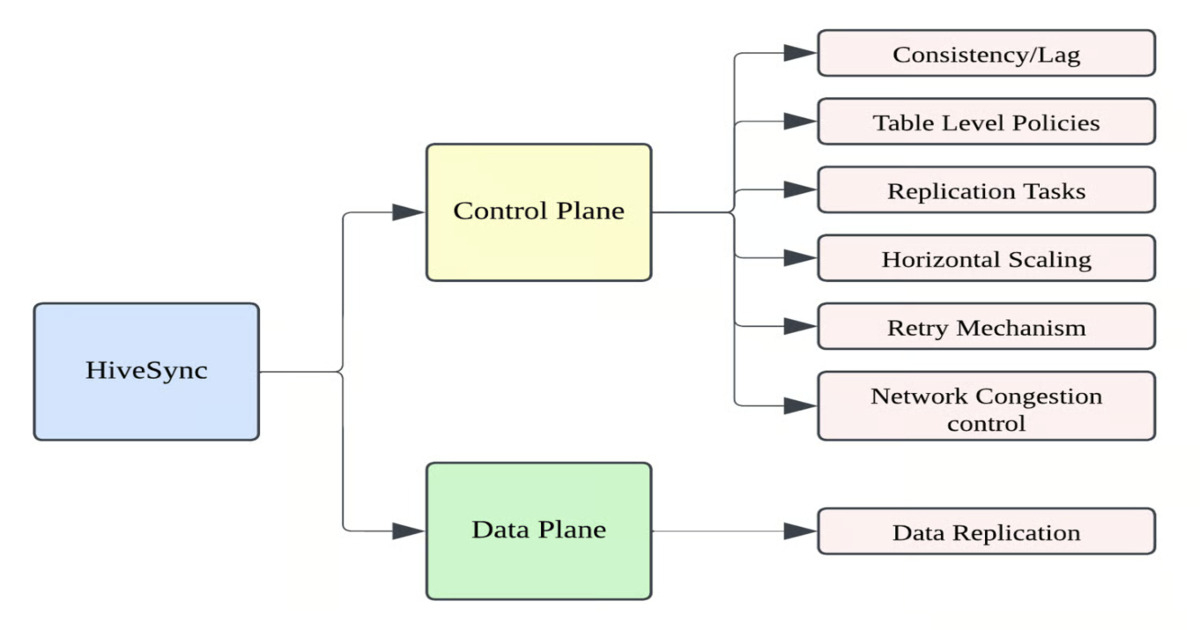

在基于Galera的环境中使用PXC复制管理器自动管理源和副本的故障转移
Percona Database Performance Blog
·

EMR和S3的跨区域应急备份恢复方案之二:亿级数据文件批量筛选恢复
亚马逊AWS官方博客
·

如何基于Percona Operator为PostgreSQL部署备用/临时集群
Percona Database Performance Blog
·

推出新的Percona MySQL Operator的GA版本:在Kubernetes上提供更多复制选项
Percona Database Performance Blog
·

桶分叉如何将GitHub风格的分叉引入对象存储
The New Stack
·
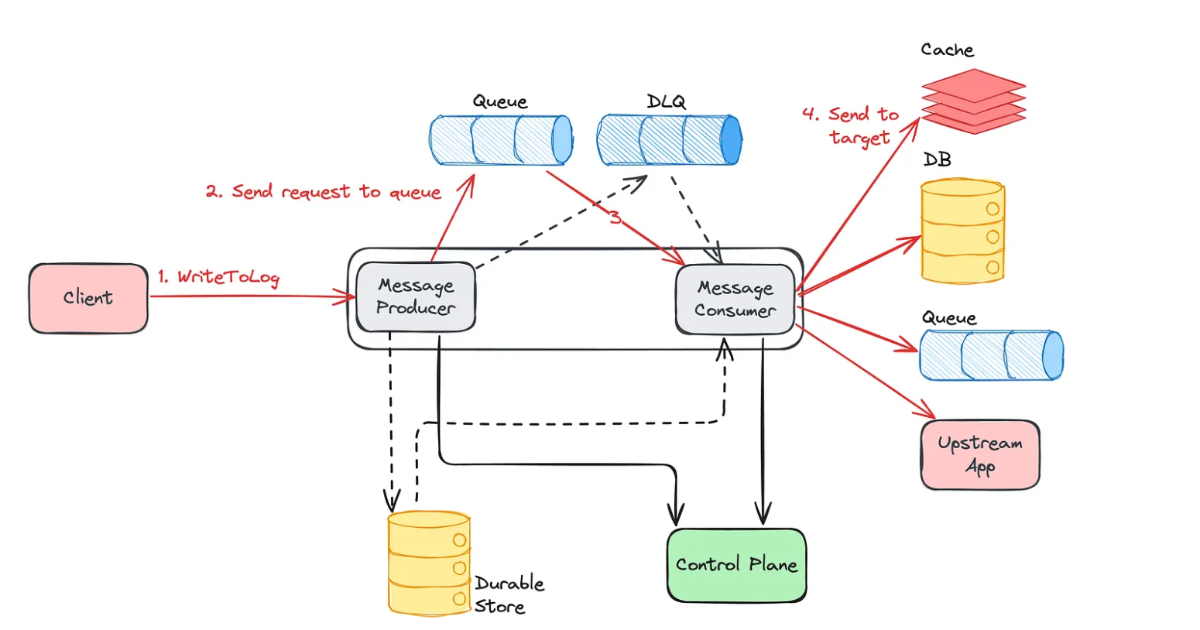
从故障到有序:Netflix通过WAL实现数据库韧性的策略
InfoQ
·
Databricks的灾难恢复管理如何帮助Capital One实现湖仓韧性
Databricks
·
