
350PB,数百万事件,一个系统:深入了解Uber的跨区域数据湖与灾难恢复
内容提要
Uber开发了HiveSync,一个分片批量复制系统,确保Hive与HDFS数据在多个区域间同步,处理每日数百万个Hive事件。HiveSync提高了数据一致性,支持灾难恢复,消除闲置硬件成本。该系统包括控制平面和数据平面,实时捕捉DDL和DML变化,确保高可用性和数据准确性。
关键要点
-
Uber开发了HiveSync,一个分片批量复制系统,确保Hive与HDFS数据在多个区域间同步,处理每日数百万个Hive事件。
-
HiveSync提高了数据一致性,支持灾难恢复,消除闲置硬件成本。
-
HiveSync最初基于开源的Airbnb ReAir项目,经过扩展,增加了分片、DAG基础的编排和控制平面与数据平面的分离。
-
ETL作业在主数据中心执行,HiveSync处理跨区域复制,确保近实时一致性。
-
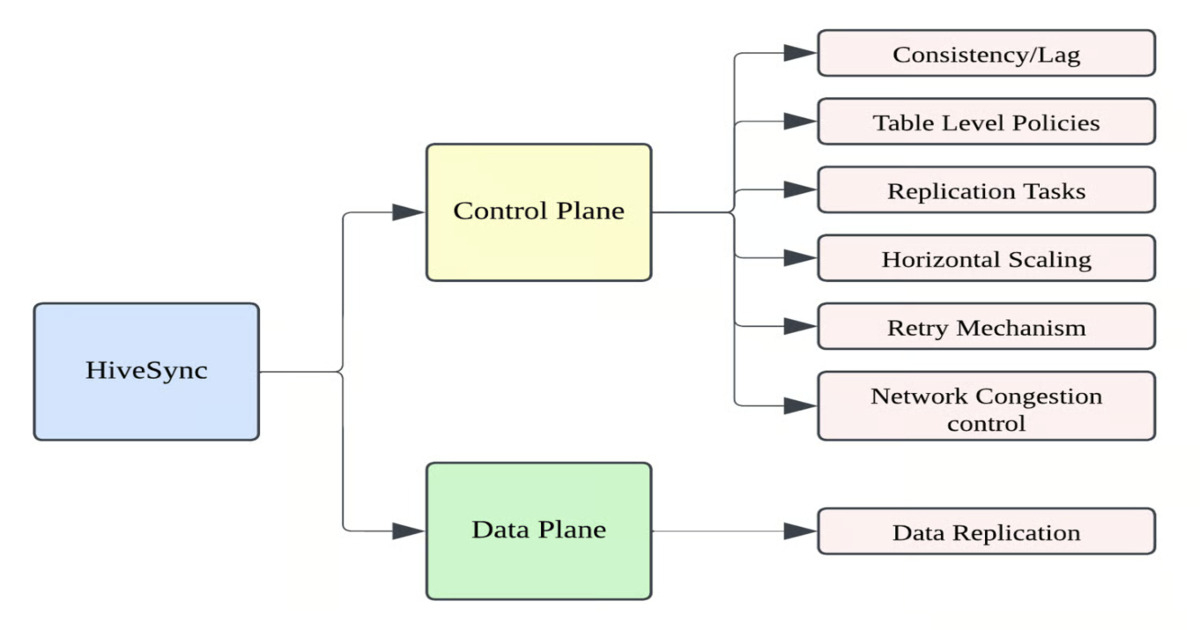
HiveSync的控制平面负责作业编排和状态管理,数据平面执行HDFS和Hive文件操作。
-
Hive Metastore事件监听器捕获DDL和DML变化,并记录到MySQL,触发复制工作流。
-
HiveSync的两个主要组件是HiveSync复制服务和数据修复服务。
-
复制服务使用Hive Metastore事件监听器实时捕获表和分区变化,并异步记录。
-
数据修复服务持续检测异常,确保数据中心之间的一致性,目标是超过99.99%的准确性。
-
HiveSync每天处理超过500万个Hive DDL和DML事件,复制约8PB的数据。
-
Uber计划扩展HiveSync以支持云复制用例,进一步利用分片、编排和修复来维护PB级数据完整性。
延伸解读
HiveSync的架构优势
HiveSync通过将控制平面与数据平面分离,提升了系统的灵活性和可维护性。控制平面负责作业编排和状态管理,而数据平面则专注于文件操作,这种设计使得系统能够高效处理大规模数据,同时确保数据一致性和高可用性。
灾难恢复能力
HiveSync的设计不仅关注数据的实时复制,还强调灾难恢复能力。通过持续监测和修复服务,系统能够在出现异常时迅速恢复数据一致性,确保业务连续性。这对于依赖数据分析和实时决策的企业尤为重要。
扩展性与未来发展
Uber计划将HiveSync扩展到云复制用例,适应不断变化的技术环境。随着数据分析和机器学习工作负载向云迁移,HiveSync的分片和编排能力将帮助企业在云环境中高效维护PB级数据的完整性。
延伸问答
HiveSync是什么,它的主要功能是什么?
HiveSync是Uber开发的一个分片批量复制系统,主要用于确保Hive与HDFS数据在多个区域间同步,处理每日数百万个Hive事件。
HiveSync如何支持灾难恢复?
HiveSync通过确保跨区域数据一致性和高可用性,支持Uber的灾难恢复策略,避免了次要区域闲置造成的硬件成本。
HiveSync的架构是怎样的?
HiveSync的架构包括控制平面和数据平面的分离,控制平面负责作业编排和状态管理,数据平面执行HDFS和Hive文件操作。
HiveSync的主要组件有哪些?
HiveSync的主要组件包括HiveSync复制服务和数据修复服务,前者负责实时捕获变化,后者检测并修复数据不一致。
HiveSync如何处理数据一致性问题?
HiveSync通过数据修复服务持续检测异常,确保数据中心之间的一致性,目标是超过99.99%的准确性。
Uber未来对HiveSync有什么计划?
Uber计划扩展HiveSync以支持云复制用例,进一步利用分片、编排和修复来维护PB级数据完整性。
