

CNCF云原生人工智能数据存储白皮书
Cloud Native Computing Foundation
·

使用 Amazon S3 Tables 优化数据湖:从Hudi 迁移到托管 Iceberg
亚马逊AWS官方博客
·
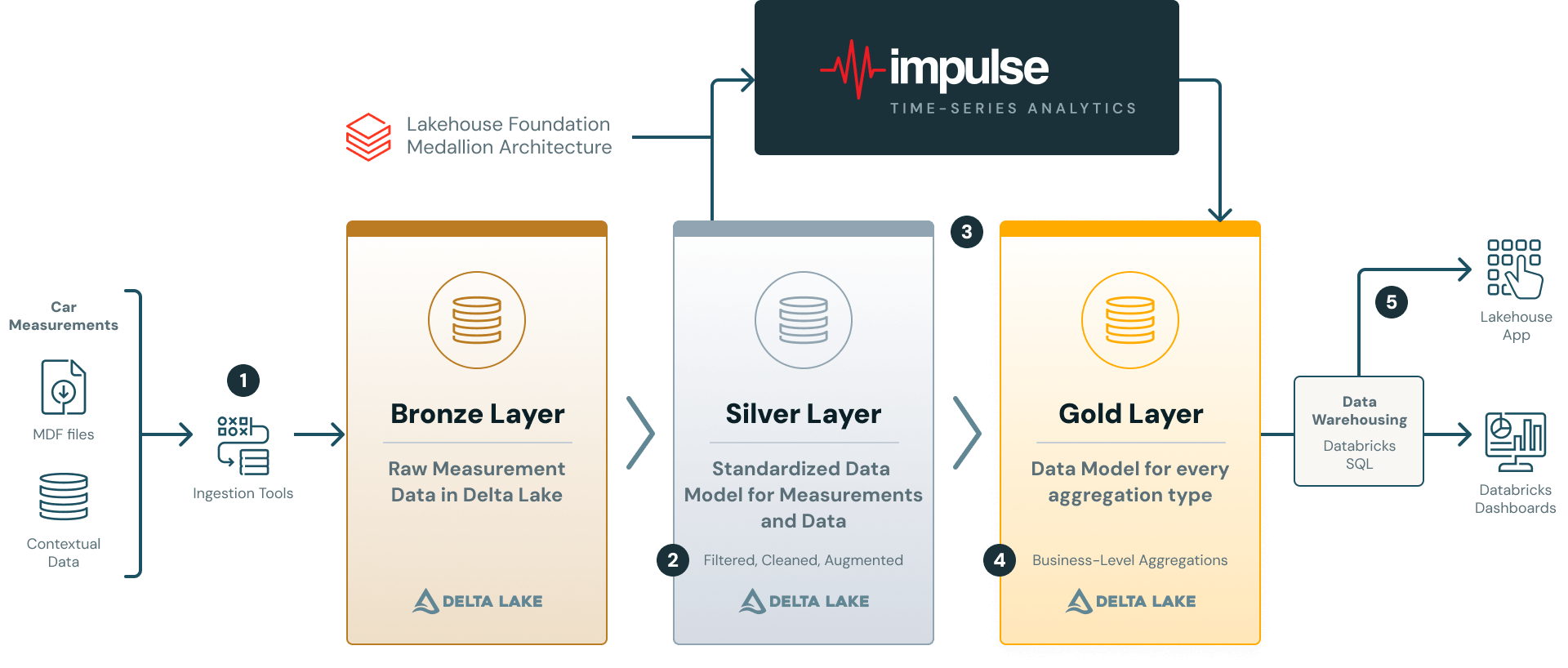
从测试台到数据湖:AVL如何通过Impulse现代化测量数据分析
Databricks
·

为AI代理打造的细致数据湖:AWS Context在推理能力上焕然一新
The New Stack
·
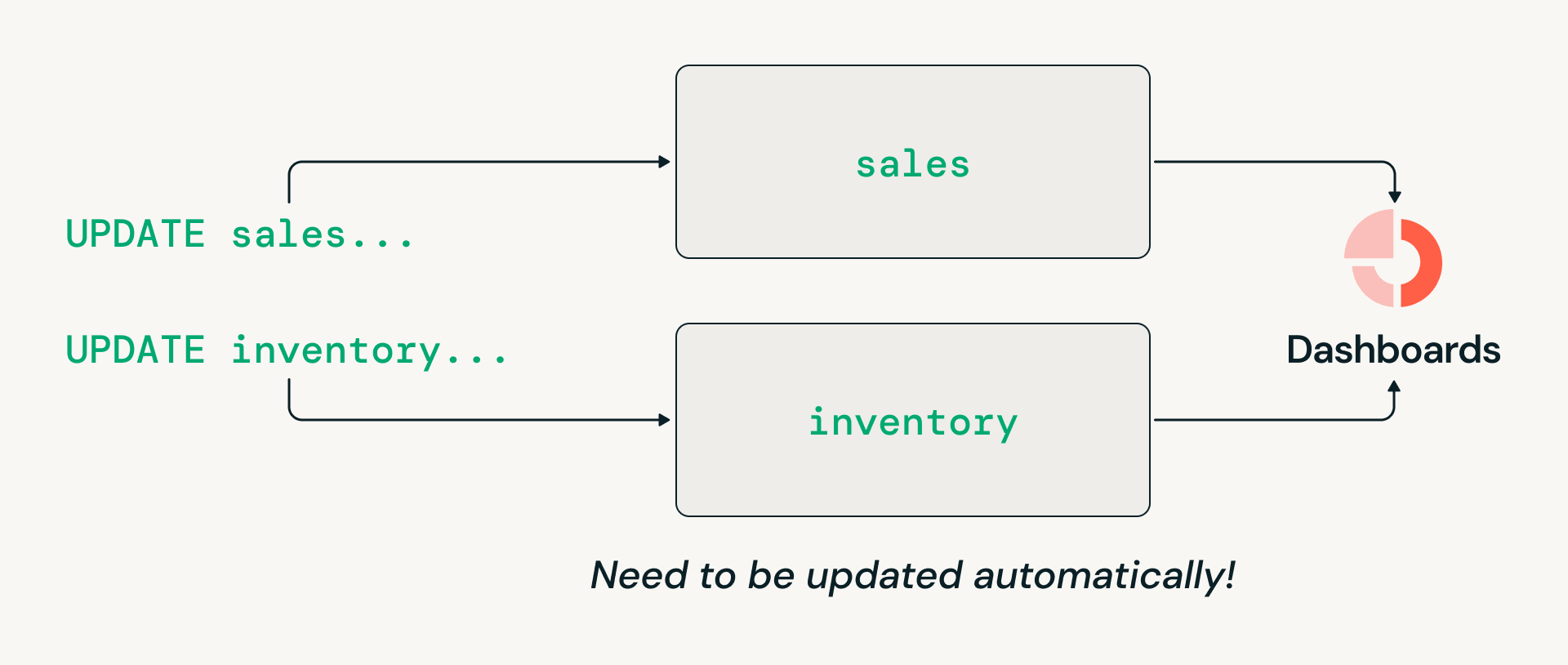
开放表格式与开放目录的融合:Catalog Commits现已全面上线
Databricks
·
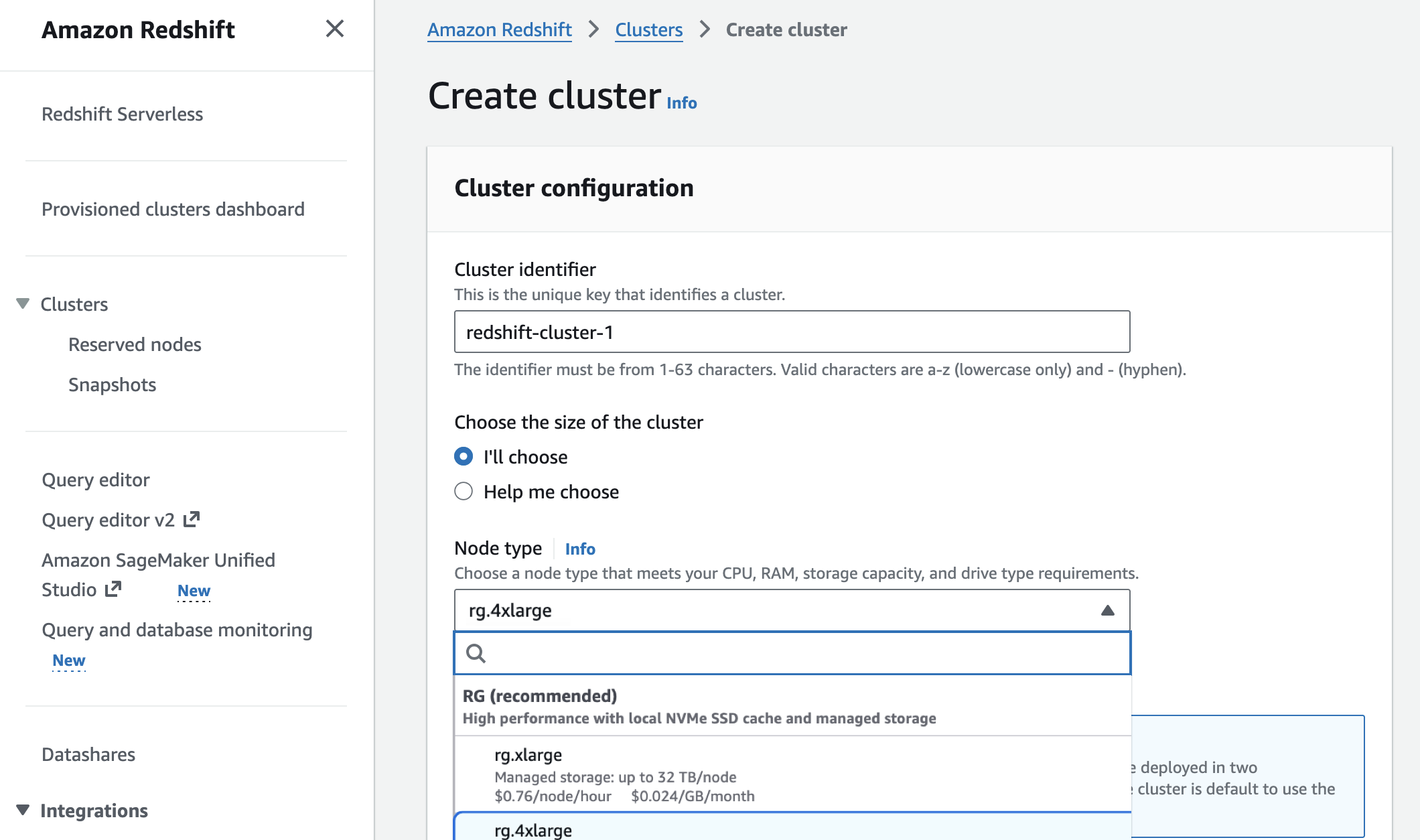

ASF项目聚焦:Apache Iceberg
The Apache Software Foundation Blog
·
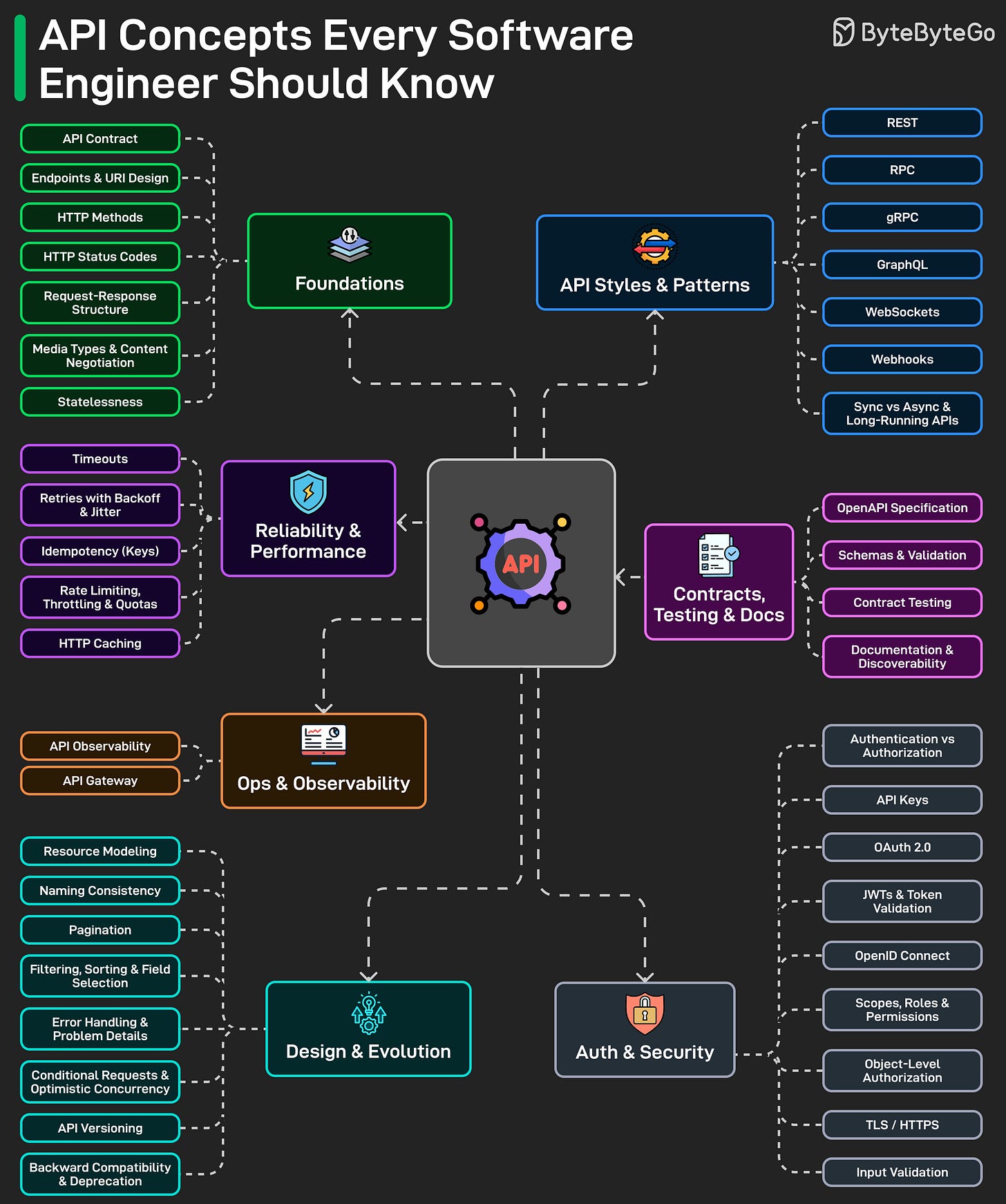
EP212:数据仓库与数据湖与数据网格
ByteByteGo Newsletter
·
