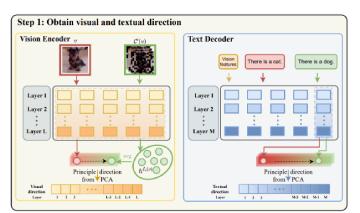
LVLM(大型视觉语言模型)存在幻觉问题,导致生成的文本与视觉输入不一致。研究人员提出了视觉和文本干预(VTI)技术,通过调整潜在空间表示来稳定视觉特征,从而减少幻觉。实验结果显示,VTI在多个基准测试中优于传统方法,强调了特征稳定性的重要性,为LVLM的实际应用提供了可靠性解决方案。
本文探讨了利用神经元激活分布(DNAs)进行图像和数据集比较,提出了一种通用视觉地点识别(VPR)解决方案,显著提升了性能。研究还介绍了StructVPR和CricaVPR等新型系统和方法,以提高特征的稳定性和鲁棒性,适用于资源受限的环境。实验结果表明,这些方法在多个基准数据集上表现优异。
完成下面两步后,将自动完成登录并继续当前操作。