
减少大型视觉语言模型中的幻觉:潜在空间引导方法
内容提要
LVLM(大型视觉语言模型)存在幻觉问题,导致生成的文本与视觉输入不一致。研究人员提出了视觉和文本干预(VTI)技术,通过调整潜在空间表示来稳定视觉特征,从而减少幻觉。实验结果显示,VTI在多个基准测试中优于传统方法,强调了特征稳定性的重要性,为LVLM的实际应用提供了可靠性解决方案。
关键要点
-
LVLM(大型视觉语言模型)存在幻觉问题,生成的文本与视觉输入不一致。
-
LVLM的幻觉问题源于预训练中的统计偏差、对语言先验的过度依赖以及特征学习偏差。
-
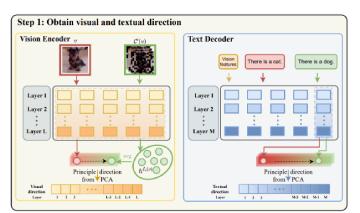
研究人员提出了视觉和文本干预(VTI)技术,通过调整潜在空间表示来稳定视觉特征,减少幻觉。
-
VTI通过预先计算受扰图像的变换方向,减少幻觉而无需额外训练成本。
-
实验结果显示,VTI在多个基准测试中优于传统方法,强调了视觉特征稳定性的重要性。
-
VTI有效解决了多模式幻觉问题,同时保持了内容质量。
-
研究表明,稳健特征表示对LVLM在现实世界中的应用至关重要。
延伸解读
LVLM的幻觉问题及其影响
LVLM(大型视觉语言模型)在生成文本时常常出现与视觉输入不一致的幻觉现象。这种问题不仅影响了模型在图像描述和视觉问答等任务中的表现,也限制了其在医疗等实际应用中的可靠性。因此,理解幻觉的成因及其对模型应用的影响至关重要。
视觉和文本干预(VTI)的创新
VTI技术通过调整潜在空间表示来稳定视觉特征,从而有效减少幻觉。这一方法的创新之处在于无需额外训练成本,且在多个基准测试中表现优于传统方法。这为LVLM的实际应用提供了新的思路,尤其是在需要高准确性的场景中。
特征稳定性的重要性
研究表明,视觉特征的稳定性对LVLM的性能至关重要。VTI通过预先计算受扰图像的特征偏移,显著提高了特征的稳定性。这一发现强调了在模型设计中考虑特征稳定性的重要性,以确保在复杂任务中的可靠性和准确性。
延伸问答
LVLM中的幻觉问题是什么?
LVLM中的幻觉问题是指生成的文本与视觉输入不一致,导致图像描述不准确或空间关系错误。
造成LVLM幻觉的原因有哪些?
造成LVLM幻觉的原因包括预训练中的统计偏差、对语言先验的过度依赖以及特征学习偏差。
什么是视觉和文本干预(VTI)技术?
VTI是一种通过调整潜在空间表示来稳定视觉特征的技术,旨在减少LVLM中的幻觉。
VTI技术如何减少LVLM中的幻觉?
VTI通过预先计算受扰图像的变换方向并将其应用于新查询,从而无需额外训练成本来减少幻觉。
VTI在实验中表现如何?
实验结果显示,VTI在多个基准测试中优于传统方法,强调了视觉特征稳定性的重要性。
LVLM的实际应用中,特征稳定性有多重要?
特征稳定性对LVLM在现实世界中的应用至关重要,有助于提高模型的可靠性和准确性。
