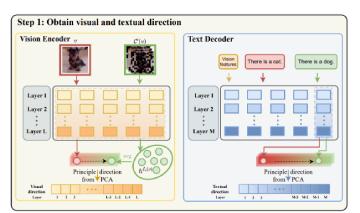
LVLM(大型视觉语言模型)存在幻觉问题,导致生成的文本与视觉输入不一致。研究人员提出了视觉和文本干预(VTI)技术,通过调整潜在空间表示来稳定视觉特征,从而减少幻觉。实验结果显示,VTI在多个基准测试中优于传统方法,强调了特征稳定性的重要性,为LVLM的实际应用提供了可靠性解决方案。
本文提出了一种新方法Fwd2Bot,用于大型视觉语言模型(LVLM)中视觉令牌的高效压缩。该方法通过双向前传训练,实现了几乎无损的压缩效果,显著提升了生成任务的压缩率,并在图像检索与组合性任务上达到了新的最先进性能。
本研究针对大型视觉语言模型(LVLMs)在多模态任务中压缩对生成性能的影响进行了深入探讨,填补了现有研究在这一领域的空白。通过引入KV缓存和权重压缩两种主要的自动回归模型压缩方式,研究展示了在多个多模态数据集上的压缩效果,以及其对性能和伦理关键指标的影响。
本研究分析了大型视觉语言模型中的对抗攻击,系统总结了传统攻击与LVLM攻击的关联与区别,为未来研究提供参考。理解攻击本质对开发更强健的系统至关重要。
本文探讨了房间到房间导航中的数据处理方法,提出基于随机游走的路径采样以减轻偏见,提升模型在未知环境中的推广能力。同时,研究介绍了利用大型语言模型(LLMs)和视觉语言模型(LVLMs)进行目标导航的框架,强调语义丰富的3D场景表示和任务特定信息的生成,以提高导航效率和准确性。
这篇论文探讨了大型视觉-语言模型(LVLMs)中的幻觉问题,提出了评估框架和无需训练的残差视觉解码方法,以减少幻觉现象。研究表明,开源 LVLMs 性能下降,通过引入更详细的视觉注释和新评估基准 RAH-Bench 提高模型准确性。此外,提出的去偏策略有效减轻了偏见,增强了生成内容的真实性。
本文探讨了多模态大型语言模型(MLLMs)在视觉地点识别中的应用,提出了Prompt-driven Visual-Linguistic Representation Learning(PVLR)框架和MultiRes-NetVLAD编码方法。这些方法在图像文本检索和多标签识别任务中显著提升了性能,鼓励对MLLMs的进一步探索。
本文探讨了大型视觉语言模型(LVLMs)中的幻觉问题,提出了改进的训练方法和评估基准,以提高模型的准确性和可靠性。研究分析了幻觉的类型、原因及现有缓解方法,并提出了新的评估框架和任务,以促进未来的研究。
本研究提出了一种新颖的图像偏置解码技术,旨在减少大规模视觉语言模型中的幻觉问题。该方法通过自适应调整和统计分析,增强生成内容的真实性,无需额外训练数据。实验结果表明,该技术显著减轻了物体幻觉,并提升了模型的识别能力,具有广泛的适用性。
本文介绍了MMMU,一个新基准,用于评估多模态模型在大学级学科知识和跨学科任务上的表现。MMMU包含11500个多模态问题,涵盖六个核心学科,旨在挑战模型进行高级推理。评估结果显示,先进模型如GPT-4V的准确率仅为56%,表明仍有改进空间,MMMU旨在推动专家级人工智能的发展。
本文介绍了多个虚假图像和假新闻检测基准的构建,包括FakeBench、FakeClass、FakeClue和FakeQA等数据集,旨在提升多模态模型在真实性检测方面的能力。研究表明,现有模型在识别虚假信息时表现中等,强调了对抗虚假信息的必要性,并提出了新方法以提高检测准确性。
本文探讨了大型视觉语言模型(LVLMs)中的幻觉问题,提出了视觉对比解码(VCD)和图像偏置解码等方法,以减少幻觉并提高模型性能。研究表明,这些方法在无需额外训练的情况下显著提升了输出准确性,并提供了幻觉评估框架及未来研究方向的建议。
本研究融合目标检测和光学字符识别模型,提高细粒度图像理解能力和多模态大型语言模型性能。实验结果显示改进后的模型在多个基准测试中表现优异,标志着多模态理解领域的重大进展。希望通过发布代码进一步探索多模态大型语言模型在细粒度多模态对话能力方面的应用。
该研究探讨了医学领域中视觉问答的挑战,并通过联合学习放射学图像的有效表示和多模态表示,创新性地增强了数据集,取得了较高的准确度。该研究推进了医学VQA,并在诊断环境中开辟了实用应用的途径。
我们提出了一种新颖的框架,camo-perceptive 视觉语言框架(CPVLF),以探索 LVLM 在伪装目标检测中的泛化能力。通过观察 LVLM 的泛化过程,我们发现其在伪装场景中准确定位物体方面存在不确定性。因此,我们提出了一种链式视觉感知方法,从语言和视觉角度增强 LVLM 对伪装场景的感知,并提高其准确定位伪装物体的能力。实验证明 CPVLF 在伪装目标检测任务中有效。
研究提出了一种新的视觉语言框架CPVLF,用于探索LVLM在伪装目标检测中的泛化能力。通过观察LVLM的泛化过程,发现其会错误感知伪装场景中的物体,并表现出一定的不确定性。因此,提出了一种链式视觉感知方法,增强LVLM对伪装场景的感知能力。实验证明CPVLF在伪装目标检测任务中有效。
完成下面两步后,将自动完成登录并继续当前操作。