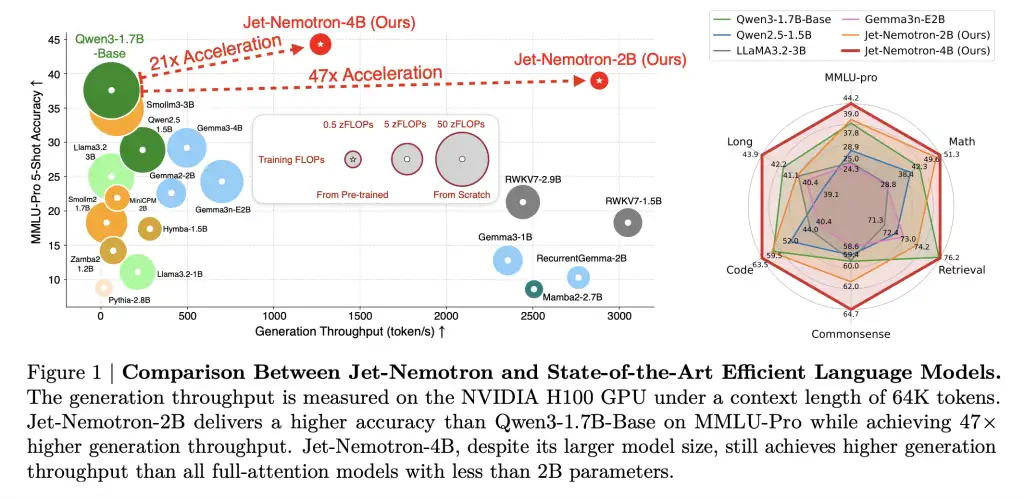
研究团队提出Jet-Nemotron,通过后神经架构搜索优化全注意力模型,显著提高生成吞吐量,同时保持或超越准确率,为高效语言模型设计开辟新路径。
NVIDIA发布了Jet-Nemotron模型系列,利用后神经架构搜索技术显著提升了大语言模型的生成吞吐量,达到53.6倍,同时保持或超越准确率。这一创新降低了计算和内存成本,使得边缘设备的大规模部署成为可能,提升了AI应用的经济性和效率。
完成下面两步后,将自动完成登录并继续当前操作。