
NVIDIA AI 发布 Jet-Nemotron:速度提升 53 倍的混合架构语言模型系列,可降低大规模推理成本 98%
内容提要
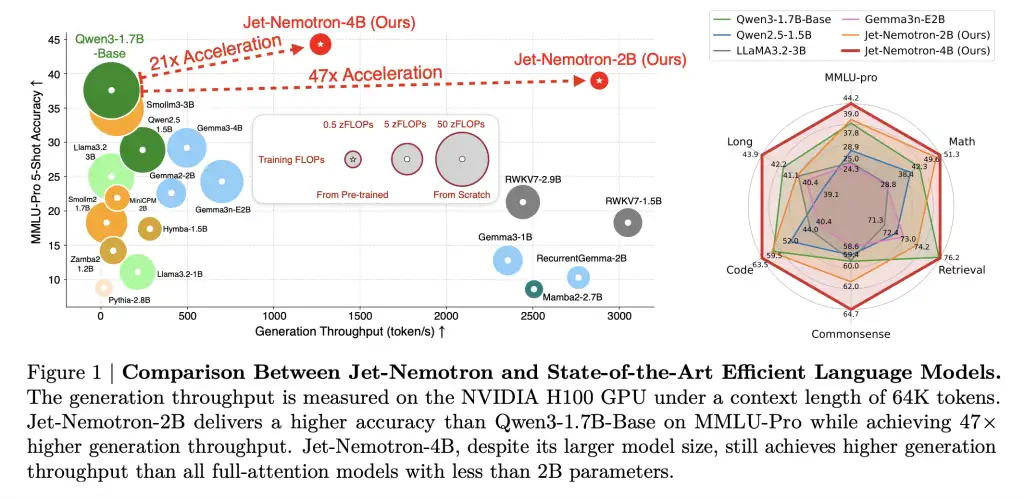
NVIDIA发布了Jet-Nemotron模型系列,利用后神经架构搜索技术显著提升了大语言模型的生成吞吐量,达到53.6倍,同时保持或超越准确率。这一创新降低了计算和内存成本,使得边缘设备的大规模部署成为可能,提升了AI应用的经济性和效率。
关键要点
-
NVIDIA发布Jet-Nemotron模型系列,生成吞吐量提升53.6倍,准确率持平或超越。
-
采用后神经架构搜索技术对现有预训练模型进行改造,降低计算和内存成本。
-
现代LLM的O(n²)自注意力机制导致高昂的计算和内存成本,限制了大规模部署。
-
PostNAS技术通过冻结知识和精准替换,优化了模型的训练和性能。
-
JetBlock模块替代全注意力机制,提升了硬件效率和准确性。
-
Jet-Nemotron模型在多个基准测试中表现优异,吞吐量和内存占用显著降低。
-
企业可实现更高的投资回报率,推理成本降低98%。
-
边缘设备上无需重新训练即可使用Jet-Nemotron,适应性强。
-
PostNAS降低了LLM架构创新的成本,促进了更快的迭代和创新。
-
Jet-Nemotron的开源将推动AI生态系统的效率提升。
延伸解读
技术创新的意义
Jet-Nemotron模型系列的发布标志着大语言模型领域的一次重大技术突破。通过后神经架构搜索技术,NVIDIA不仅提升了生成吞吐量,还降低了计算和内存成本。这一创新使得边缘设备的部署变得更加可行,推动了AI应用的普及和经济性。
企业应用的潜力
Jet-Nemotron的推出为企业提供了更高的投资回报率,推理成本降低98%意味着企业可以以更低的成本服务更多用户。这将使得许多曾经昂贵的AI任务变得可行,推动企业在实时文档处理和长上下文任务等领域的应用。
研究与开发的机遇
PostNAS技术的引入降低了大语言模型架构创新的门槛,使研究人员能够更快地进行实验和迭代。通过在冻结的主干模型上进行架构搜索,研究人员可以在短时间内测试新模块的有效性,从而加速AI技术的发展。
延伸问答
Jet-Nemotron模型系列的主要优势是什么?
Jet-Nemotron模型系列的生成吞吐量提升了53.6倍,同时保持或超越了准确率,显著降低了计算和内存成本。
PostNAS技术是如何优化大语言模型的?
PostNAS技术通过冻结知识和精准替换,优化了现有预训练模型,降低了训练成本并提升了性能。
Jet-Nemotron在边缘设备上的应用前景如何?
Jet-Nemotron在边缘设备上无需重新训练即可使用,适应性强,能够在内存受限的环境中高效运行。
JetBlock模块的作用是什么?
JetBlock模块替代了计算密集型的全注意力机制,提升了硬件效率和模型的准确性。
Jet-Nemotron如何影响企业的投资回报率?
Jet-Nemotron使得大规模推理成本降低98%,同等成本下可以服务更多用户,从而提升企业的投资回报率。
Jet-Nemotron的开源对AI生态系统有什么影响?
Jet-Nemotron的开源将推动AI生态系统的效率提升,使更多社区能够改进模型,实现更高效的创新。
