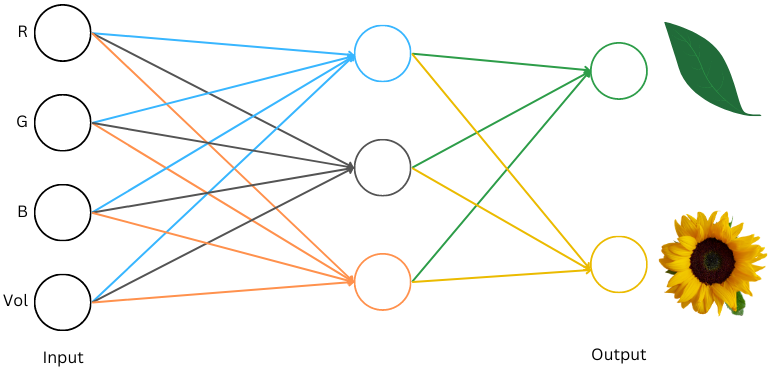
本文介绍了大语言模型(LLM)的基本原理,重点讨论了神经网络的构建、训练过程及其生成语言的能力。通过简单的数学概念,解释了如何将输入数据转化为数字,并通过训练优化模型的权重。文章还探讨了嵌入、子词分词器和自注意力机制等关键技术,阐明了现代LLM的有效性及其在生成语言中的应用。
完成下面两步后,将自动完成登录并继续当前操作。