
用初中数学理解LLM工作原理
内容提要
本文介绍了大语言模型(LLM)的基本原理,重点讨论了神经网络的构建、训练过程及其生成语言的能力。通过简单的数学概念,解释了如何将输入数据转化为数字,并通过训练优化模型的权重。文章还探讨了嵌入、子词分词器和自注意力机制等关键技术,阐明了现代LLM的有效性及其在生成语言中的应用。
关键要点
-
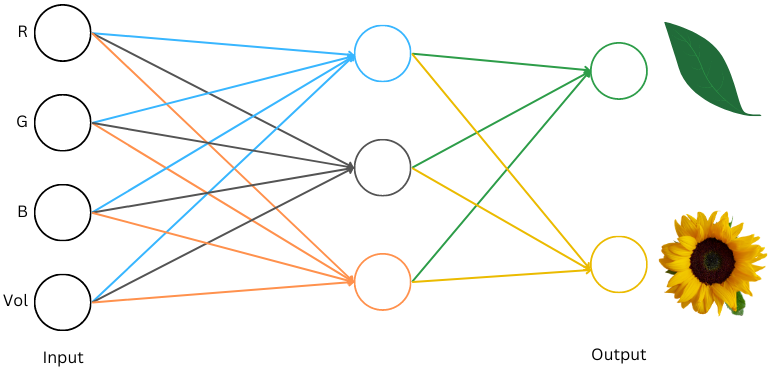
大语言模型(LLM)基于神经网络,输入和输出均为数字。
-
神经网络的构建包括输入层、隐藏层和输出层,使用权重和激活函数进行计算。
-
模型训练通过调整权重以最小化损失,使用梯度下降法进行优化。
-
神经网络可以通过输入字符序列生成下一个字符,形成生成式AI。
-
嵌入技术用于将字符或单词映射为向量,以提高模型性能。
-
子词分词器将单词拆分为更小的单位,以减少词汇量并提高模型理解能力。
-
自注意力机制允许模型根据上下文动态调整权重,提高语言生成的准确性。
-
Softmax函数将输出转换为概率,帮助模型选择最可能的输出。
-
残差连接和层归一化技术提高了深度网络的训练效率和稳定性。
-
Dropout技术用于防止模型过拟合,通过随机丢弃部分神经元连接来增强模型的泛化能力。
-
多头注意力机制并行处理多个注意力模块,增强模型的表达能力。
-
Transformer架构通过编码器和解码器的组合,提升了语言模型的性能和训练效率。
延伸解读
神经网络的基本构建
大语言模型(LLM)依赖于神经网络的结构,主要包括输入层、隐藏层和输出层。理解这些层的功能和相互作用是掌握LLM工作原理的基础。输入层负责接收数字化的输入数据,隐藏层通过权重和激活函数进行计算,输出层则生成最终的预测结果。掌握这些基本构建块有助于理解更复杂的模型架构。
模型训练的挑战
训练神经网络时,损失函数的最小化是关键目标。使用梯度下降法调整权重时,可能会遇到梯度消失或梯度爆炸的问题,这会影响模型的训练效果。此外,现代大语言模型通常包含数十亿个参数,训练过程需要大量计算资源,因此在实际应用中,如何高效地进行模型训练是一个重要的挑战。
自注意力机制的优势
自注意力机制使得模型能够根据上下文动态调整权重,从而更好地理解语言中的依赖关系。这种机制允许模型在处理长文本时,关注到更重要的词汇,提高了生成语言的准确性。理解自注意力机制的工作原理,有助于深入掌握现代大语言模型的强大能力。
嵌入技术的应用
嵌入技术通过将字符或单词映射为向量,提升了模型的表现。与单一数字表示相比,使用向量能够更好地捕捉语言的复杂性和丰富性。训练嵌入向量的过程与训练模型参数类似,成功的嵌入可以在不同模型中复用,进一步提高了模型的效率和效果。
延伸问答
大语言模型(LLM)是如何工作的?
大语言模型基于神经网络,通过将输入数据转化为数字,训练模型以生成语言。模型通过调整权重来优化输出,使用技术如嵌入、自注意力机制等来提高性能。
神经网络的训练过程是怎样的?
神经网络的训练过程包括初始化权重、输入训练数据、计算损失并通过梯度下降法调整权重,以最小化损失。这个过程会重复多次,直到模型收敛。
什么是自注意力机制,它有什么作用?
自注意力机制允许模型根据上下文动态调整权重,从而更好地理解句子中各个单词之间的关系,提高语言生成的准确性。
嵌入技术在LLM中有什么重要性?
嵌入技术用于将字符或单词映射为向量,帮助模型更好地理解和处理语言,提高生成语言的能力和准确性。
什么是多头注意力机制?
多头注意力机制是Transformer架构中的关键模块,它通过并行多个注意力模块来增强模型的表达能力,从而更好地捕捉输入数据中的信息。
LLM如何生成语言?
LLM通过接收字符序列并预测下一个字符,逐步生成完整的句子。模型利用训练过程中学习到的权重和上下文信息来做出预测。
