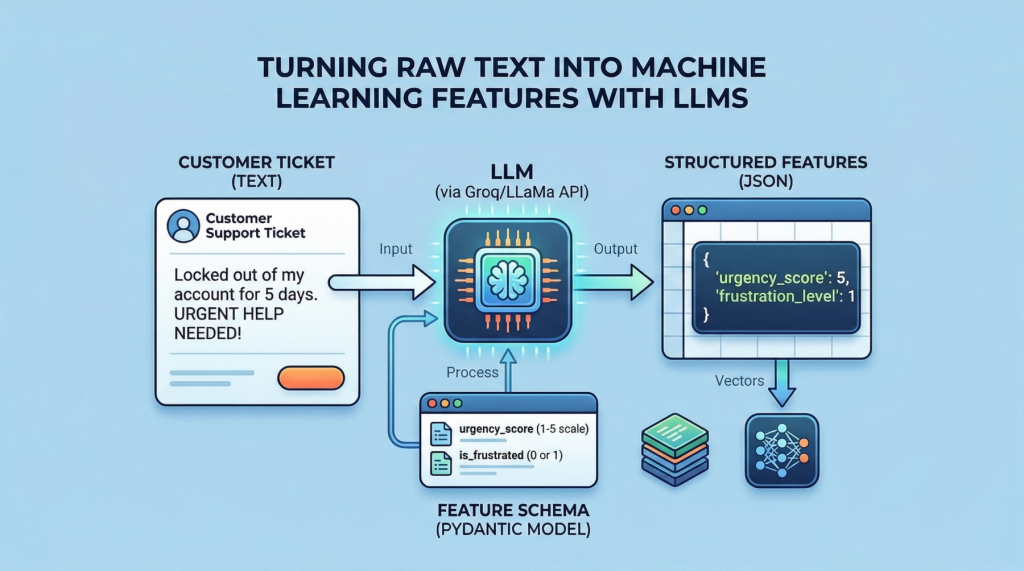
本文介绍了如何利用预训练的大型语言模型(LLM)从文本中提取结构化特征,并与数值列结合以训练监督分类器。内容包括创建混合文本和数值字段的数据集、使用Groq托管的LLaMA模型提取特征,以及在工程化表格数据集上训练和评估分类器的过程。通过将非结构化数据转化为结构化表格数据,提升机器学习模型的预测能力。
完成下面两步后,将自动完成登录并继续当前操作。