
从文本到表格:利用大型语言模型进行表格数据的特征工程
内容提要
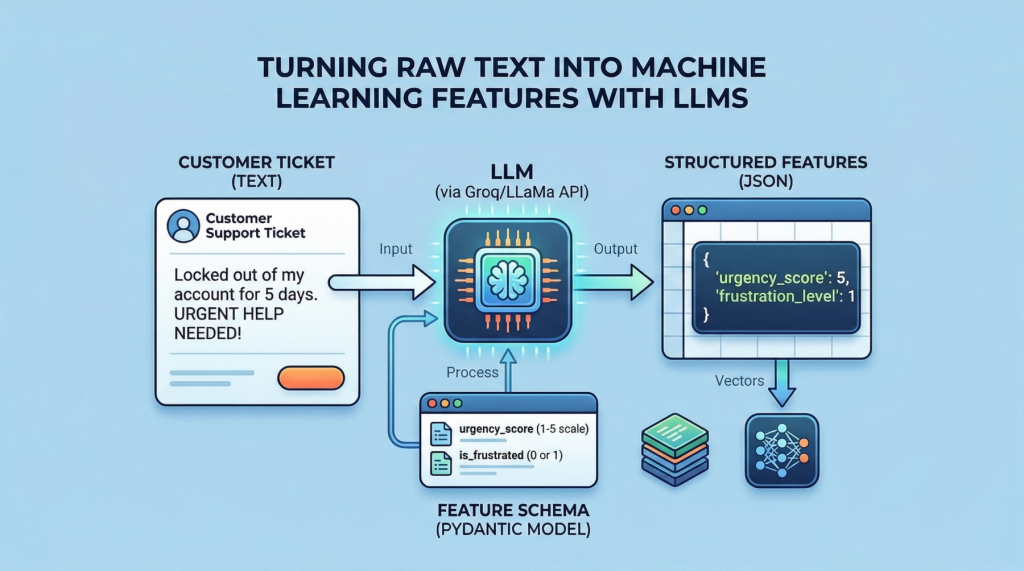
本文介绍了如何利用预训练的大型语言模型(LLM)从文本中提取结构化特征,并与数值列结合以训练监督分类器。内容包括创建混合文本和数值字段的数据集、使用Groq托管的LLaMA模型提取特征,以及在工程化表格数据集上训练和评估分类器的过程。通过将非结构化数据转化为结构化表格数据,提升机器学习模型的预测能力。
关键要点
-
利用预训练的大型语言模型(LLM)从文本中提取结构化特征,并与数值列结合以训练监督分类器。
-
创建混合文本和数值字段的数据集,包括客户支持票据的文本描述和结构化数值特征。
-
使用Groq托管的LLaMA模型提取特征,定义所需的表格特征并将其转化为JSON格式。
-
通过将提取的特征与原始数据集结合,生成最终的工程化表格数据集。
-
在工程化表格数据集上训练和评估随机森林分类器,展示分类模型的性能指标。
延伸解读
大型语言模型的应用场景
虽然大型语言模型(LLM)通常用于自然语言处理,但它们在特征工程中同样具有重要价值。通过将非结构化文本转化为结构化数据,LLM能够提升机器学习模型的预测能力。这种转化不仅限于文本分类,还可以应用于其他领域,如客户支持和市场分析。
数据集构建的注意事项
在创建混合文本和数值字段的数据集时,数据的多样性和代表性至关重要。本文使用的合成数据集虽然便于演示,但在实际应用中,真实数据的复杂性和多样性会影响模型的表现。因此,建议在实际项目中使用更大且更具代表性的数据集。
成本与效率的平衡
调用LLM进行特征提取时,处理大规模数据集可能会导致高成本和延迟。为提高效率,建议批量请求和缓存结果,以减少重复调用。此外,实施重试机制以应对网络错误和速率限制,可以显著提升数据处理的可靠性和经济性。
延伸问答
如何利用大型语言模型提取文本特征?
可以使用预训练的大型语言模型从文本中提取结构化特征,并将其与数值列结合,以训练监督分类器。
生成混合文本和数值字段的数据集的步骤是什么?
首先创建一个包含文本描述和结构化数值特征的合成数据集,然后将这些数据用于分类模型的训练。
如何使用Groq托管的LLaMA模型提取特征?
通过定义所需的表格特征,并使用Groq托管的LLaMA模型将文本转化为JSON格式的结构化特征。
在工程化表格数据集上训练分类器的过程是怎样的?
将提取的特征与原始数据结合后,使用随机森林分类器进行训练和评估,并输出分类模型的性能指标。
使用大型语言模型进行特征工程的优势是什么?
通过将非结构化数据转化为结构化表格数据,可以提升机器学习模型的预测能力。
在处理大型数据集时,如何优化LLM的调用?
可以通过批量请求、缓存结果和实现重试机制来优化LLM的调用,以提高效率和降低成本。
