

从零开始构建RAG系统 — 总结与未来展望
mongona news
·

安东尼·佩格:您的 AI 应用在 PostgreSQL 上运行。现在,无需从头开始即可使其准备好投入生产
Planet PostgreSQL
·

什么是pgvector?
Databricks
·
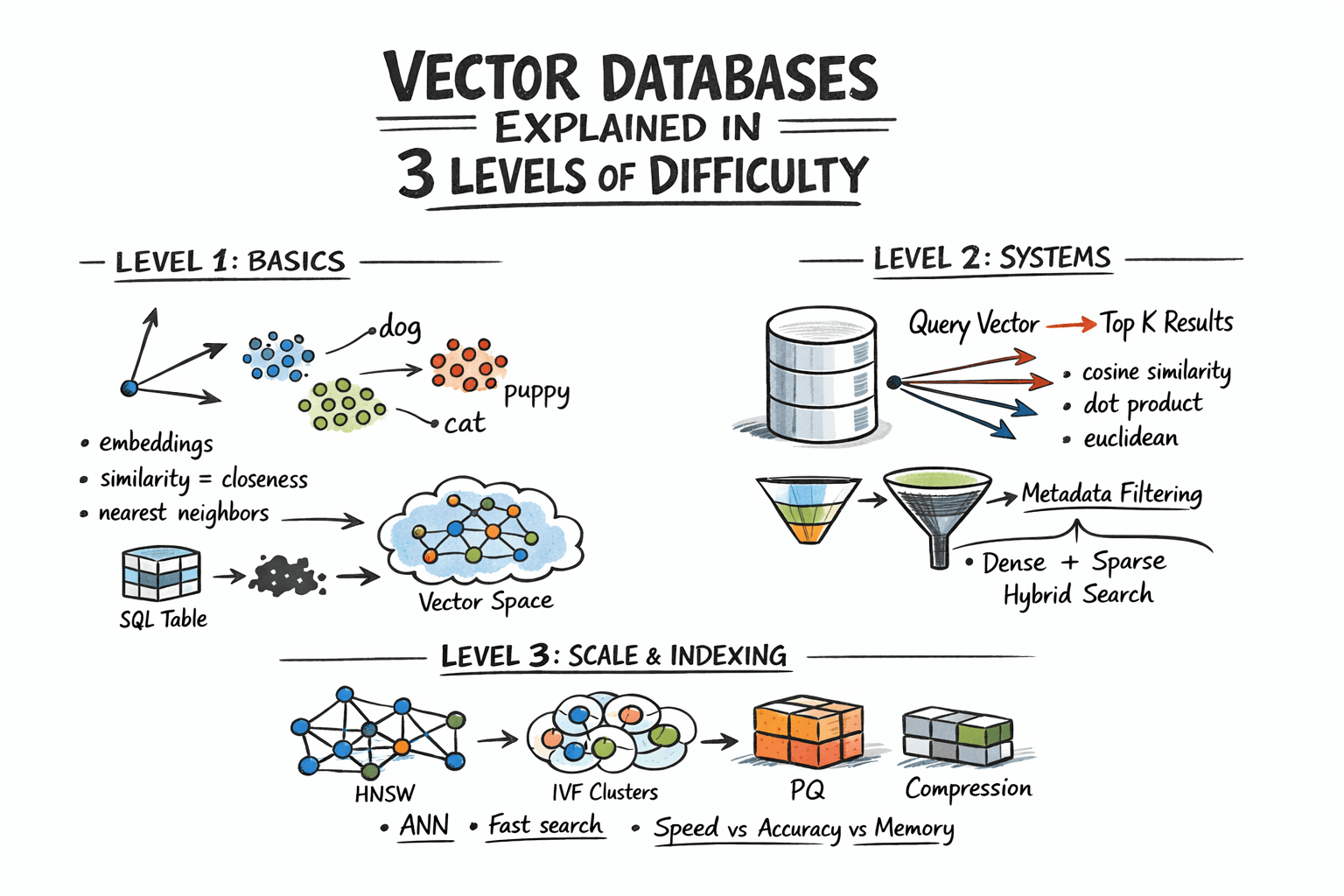
向量数据库的三种难度级别解析
MachineLearningMastery.com
·

Redis中的向量索引:算法、混合搜索与扩展
Redis Blog
·



推出Vector Buckets
Blog - Supabase
·

机器学习向量数据库完全指南
MachineLearningMastery.com
·
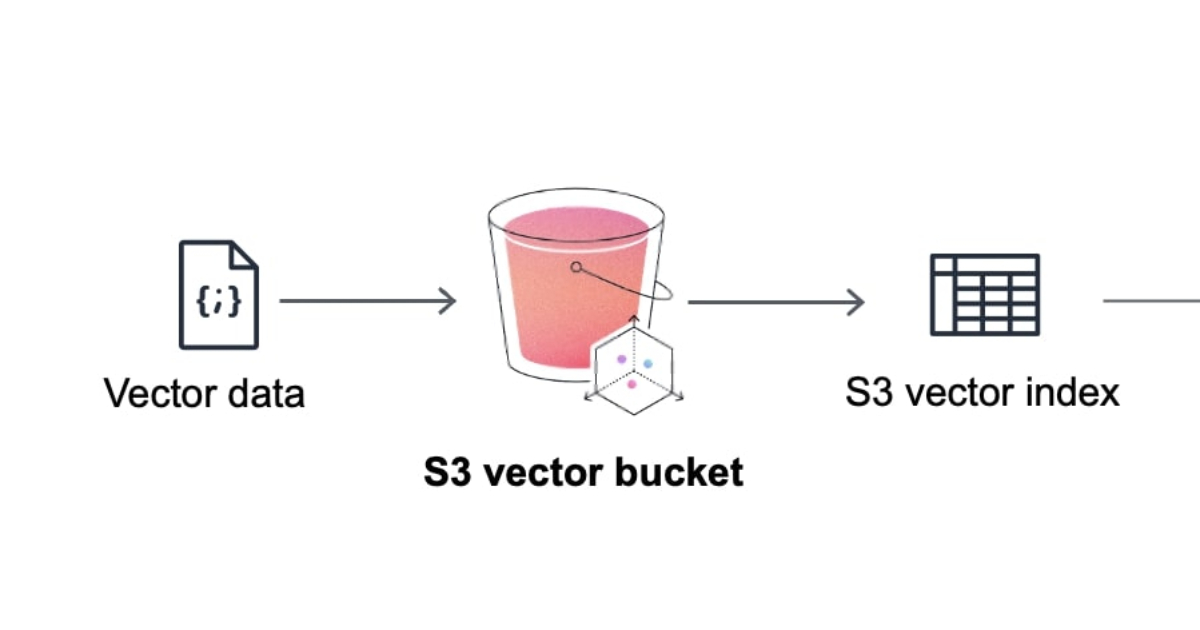
AWS在Amazon S3上推出向量功能
InfoQ
·

Redis 8引入向量集,并在Redis Cloud Essentials上预览
Redis Blog
·

人工智能代理如何记忆:向量存储在大型语言模型记忆中的作用
freeCodeCamp.org
·

pgvector:企业AI战略中至关重要的PostgreSQL组件
Percona Database Performance Blog
·

实践中的向量搜索:使用FAISS和Chroma进行嵌入
DEV Community
·

MicroNN:一种可更新的设备端磁盘驻留向量数据库
Apple Machine Learning Research
·

宣布向量集合:Redis的新数据类型,用于向量相似性
Redis Blog
·

快速提示:如何使用Ollama、DeepSeek-R1和SingleStore构建本地LLM应用
DEV Community
·
