
向量数据库的三种难度级别解析
内容提要
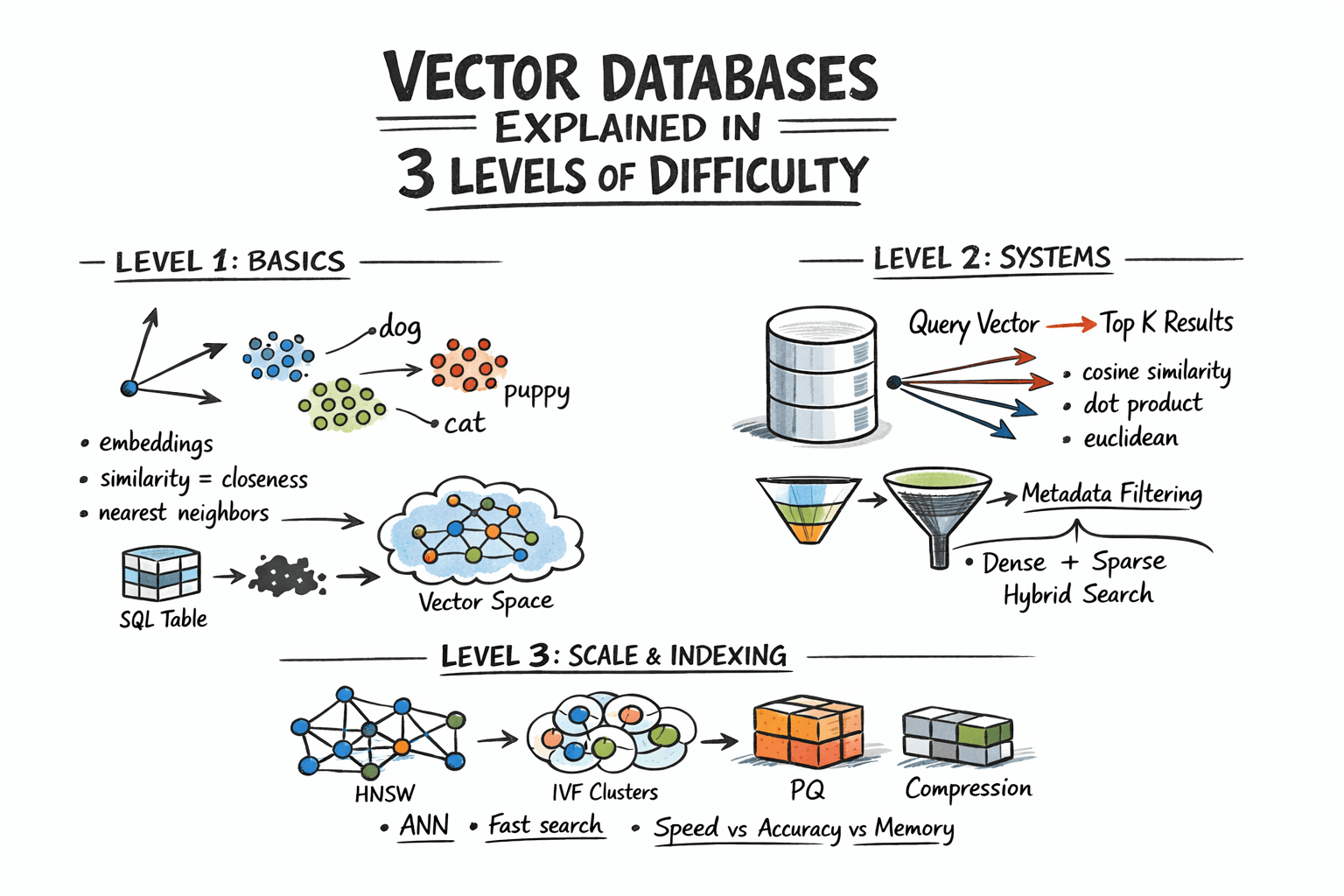
向量数据库通过将非结构化数据转换为向量,支持相似性搜索。它们采用近似最近邻算法提高检索速度,解决大规模数据搜索问题。主要技术包括HNSW、IVF和PQ等索引方法,结合元数据过滤和混合检索,提升搜索精度和效率。
关键要点
-
向量数据库通过将非结构化数据转换为向量,支持相似性搜索。
-
嵌入模型将原始内容转换为向量,使得几何接近度对应于语义相似性。
-
近似最近邻算法解决了大规模数据搜索问题,提高了检索速度。
-
主要的索引技术包括HNSW、IVF和PQ,分别在速度、内存使用和召回率之间进行权衡。
-
混合检索结合了向量相似性和元数据过滤,提升了搜索精度和效率。
-
向量数据库可以通过分片来扩展,处理超过50-100百万个向量的数据集。
延伸解读
向量数据库的应用场景
向量数据库特别适合处理非结构化数据,如文本、图像和音频等。这些数据无法通过传统的精确匹配方式进行检索,因此向量数据库通过将数据转化为向量,利用相似性搜索来满足需求。对于需要快速检索相似内容的应用场景,如推荐系统和搜索引擎,向量数据库提供了有效的解决方案。
索引技术的权衡
在选择向量数据库的索引技术时,HNSW、IVF和PQ各有优缺点。HNSW在速度和召回率上表现优异,但内存消耗较大;IVF则在内存使用上更为高效,但速度稍慢;PQ通过压缩向量显著降低内存需求,适合大规模数据集。用户需根据具体应用场景和资源限制进行选择。
混合检索的优势
混合检索结合了向量相似性和元数据过滤,能够在保证语义理解的同时,提升检索的精确度。这种方法特别适用于需要特定条件筛选的查询,如用户特定的历史记录或时间限制。通过合理配置混合检索策略,可以显著提高用户体验。
延伸问答
向量数据库如何支持相似性搜索?
向量数据库通过将非结构化数据转换为向量,使得几何接近度对应于语义相似性,从而支持相似性搜索。
近似最近邻算法的作用是什么?
近似最近邻算法解决了大规模数据搜索问题,提高了检索速度,允许在不逐一比较所有向量的情况下找到相似项。
HNSW、IVF和PQ这三种索引技术有什么区别?
HNSW在速度和召回率上表现优异但内存占用高,IVF内存使用较少但速度稍慢,PQ通过压缩向量显著减少内存使用,适合大规模数据集。
什么是混合检索,它如何提高搜索精度?
混合检索结合了向量相似性和元数据过滤,允许用户在搜索时同时考虑语义相似性和特定属性,从而提高搜索精度。
向量数据库如何扩展以处理大规模数据?
向量数据库可以通过分片来扩展,将向量空间划分到多个节点上,从而处理超过50-100百万个向量的数据集。
在选择向量数据库时应该考虑哪些因素?
选择向量数据库时应考虑性能、过滤能力、是否需要管理服务以及数据集的规模等因素。
