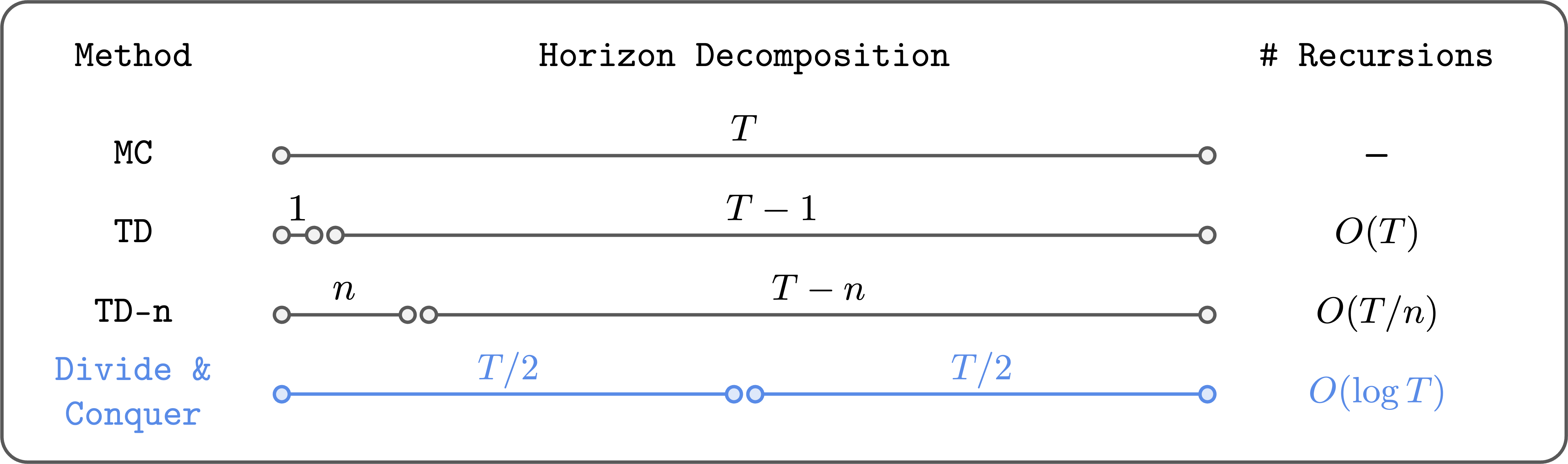
本文介绍了一种基于“分而治之”范式的强化学习算法,旨在解决传统时间差学习在长时间任务中的可扩展性问题。该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。通过将轨迹分为两个相等的部分,算法减少了贝尔曼递归的次数,从而降低了误差累积。最新的Transitive RL算法在复杂任务中表现优异,超越了许多传统方法,展示了分而治之在强化学习中的潜力。
本研究提出了一种基于内核的离线策略梯度方法,通过用户反馈优化大型语言模型生成个性化句子,显著降低方差并抑制偏差,特别适用于电影推荐描述的生成。
本文针对强化学习中的延迟奖励问题,提出了对近端策略优化(PPO)算法的两项增强,结合离线与在线策略,并引入基于时间窗口的奖励塑造机制,以提高学习效率和性能。
本文介绍了一种新算法“Discriminator-Actor-Critic”,旨在解决基于对抗模仿学习的隐式偏差和复杂性问题。该算法通过离线策略强化学习降低交互复杂度,并设计无偏差奖励函数,适用于多种任务。研究还探讨了生成对抗模仿学习的理论性质,提出了优化算法和新颖的观察学习框架,显著提升了机器人控制策略的学习性能。
本文研究了强化学习中的多个关键问题,包括价值迭代的鲁棒性、Lipschitz连续模型的影响以及离线强化学习策略的性能下限。提出了新的算法和理论结果,分析了模型误差对策略选择的影响,并提供了实证结果,展示了在不同设置下的性能界限。
完成下面两步后,将自动完成登录并继续当前操作。