
无时间差学习的强化学习
内容提要
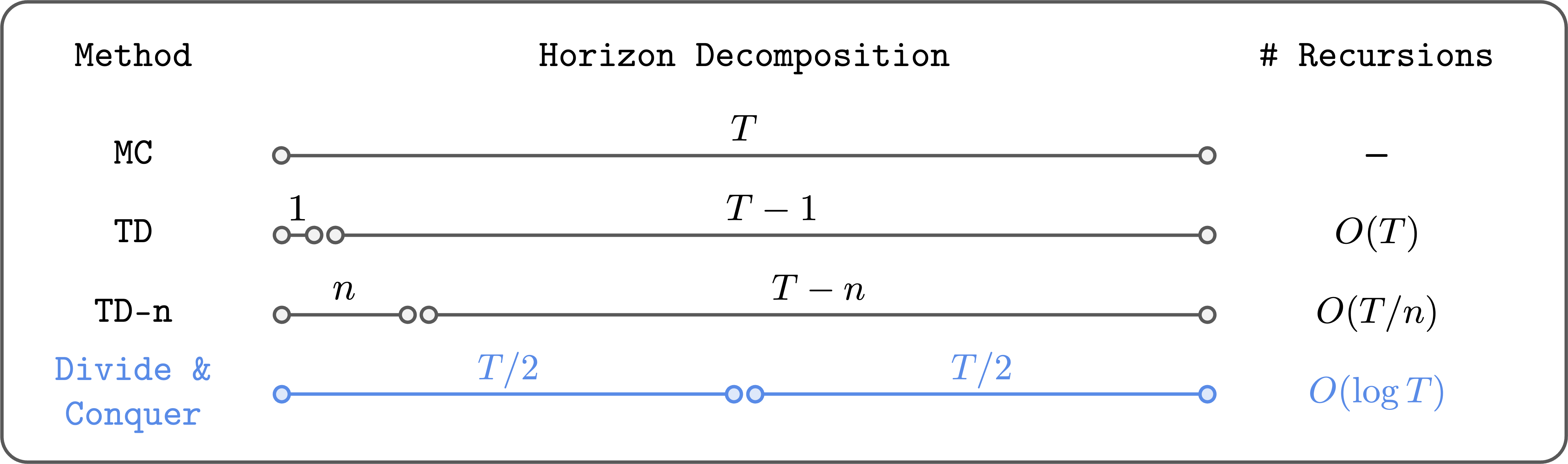
本文介绍了一种基于“分而治之”范式的强化学习算法,旨在解决传统时间差学习在长时间任务中的可扩展性问题。该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。通过将轨迹分为两个相等的部分,算法减少了贝尔曼递归的次数,从而降低了误差累积。最新的Transitive RL算法在复杂任务中表现优异,超越了许多传统方法,展示了分而治之在强化学习中的潜力。
关键要点
-
本文介绍了一种基于“分而治之”范式的强化学习算法,旨在解决传统时间差学习在长时间任务中的可扩展性问题。
-
该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。
-
通过将轨迹分为两个相等的部分,算法减少了贝尔曼递归的次数,从而降低了误差累积。
-
最新的Transitive RL算法在复杂任务中表现优异,超越了许多传统方法,展示了分而治之在强化学习中的潜力。
-
Transitive RL算法通过限制子目标的搜索空间和使用期望回归,解决了选择最优子目标的问题。
-
在OGBench基准测试中,Transitive RL在长时间任务中表现最佳,超越了许多强基线。
-
未来的研究方向包括将Transitive RL扩展到常规的基于奖励的强化学习任务,以及处理随机环境的挑战。
延伸解读
分而治之的优势
分而治之的强化学习算法通过将轨迹分为两个部分,显著减少了贝尔曼递归的次数。这种方法不仅降低了误差累积的风险,还避免了传统方法中需要调节超参数的问题,提供了一种更为高效的解决方案。
离线策略的应用场景
离线策略强化学习在数据收集成本高的领域(如机器人、医疗等)具有重要应用价值。该算法能够充分利用历史数据,提升学习效率,尤其在数据稀缺的情况下,展现出其独特的优势。
Transitive RL的挑战
尽管Transitive RL在复杂任务中表现优异,但选择最优子目标的过程仍然是一个挑战。在大规模状态空间中,如何有效地限制搜索范围并找到合适的子目标,仍需进一步研究和优化。
延伸问答
什么是无时间差学习的强化学习算法?
无时间差学习的强化学习算法基于“分而治之”范式,旨在解决传统时间差学习在长时间任务中的可扩展性问题。
Transitive RL算法的主要优势是什么?
Transitive RL算法通过减少贝尔曼递归的次数,降低了误差累积,并在复杂任务中表现优异,超越了许多传统方法。
该算法如何处理长时间任务中的数据收集问题?
该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。
分而治之的强化学习算法是如何减少贝尔曼递归的?
通过将轨迹分为两个相等的部分,分而治之算法可以减少贝尔曼递归的次数,从而降低误差累积。
Transitive RL在OGBench基准测试中的表现如何?
Transitive RL在OGBench基准测试中表现最佳,超越了许多强基线,尤其是在长时间任务中。
未来的研究方向有哪些?
未来的研究方向包括将Transitive RL扩展到常规的基于奖励的强化学习任务,以及处理随机环境的挑战。
