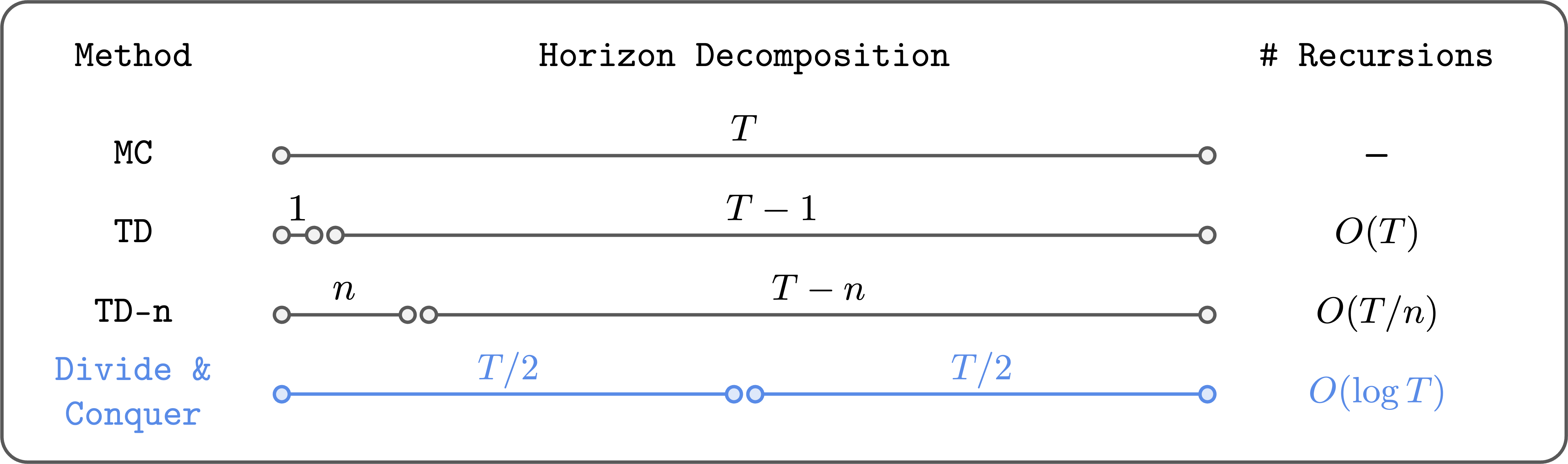
本文介绍了一种基于“分而治之”范式的强化学习算法,旨在解决传统时间差学习在长时间任务中的可扩展性问题。该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。通过将轨迹分为两个相等的部分,算法减少了贝尔曼递归的次数,从而降低了误差累积。最新的Transitive RL算法在复杂任务中表现优异,超越了许多传统方法,展示了分而治之在强化学习中的潜力。
快速排序是一种高效的排序算法,采用“分而治之”的策略,适用于大数据集。尽管在大多数情况下表现良好,但在处理几乎有序的数据时效率较低且不稳定。广泛应用于数据库、操作系统和编程语言中。
分而治之(DC)和自我完善(SR)是O1模型推理能力的核心。DC通过将复杂问题拆分为子问题来提高解决效率,而SR则通过自我评估和迭代改进来提升答案的准确性。这两种模式增强了模型处理复杂任务的能力,促进了深度理解。
归并排序是一种高效、简单和稳定的排序算法,基于“分而治之”策略。它将一个复杂问题拆分成多个较小的问题,然后将这些问题的解合并以解决原始问题。归并排序的时间复杂度为O(N∗logN),空间复杂度为O(N)。它在排序过程中保持相等元素的相对顺序不变。归并排序是广泛使用的排序方法,具有清晰的算法结构和稳定的排序性能。
快速排序是一种基于比较的排序算法,使用分而治之的策略。它适用于双向链表,具有高效、就地排序和良好的平均性能等优势。通过选择良好的枢轴和随机化方法,可以降低最坏情况下的时间复杂度。快速排序是一种灵活有效的排序算法。
快速排序是一种用于对数组进行排序的算法,它使用分而治之的策略。它选择一个枢轴元素,并根据其他元素的大小将数组划分为两个子数组。然后,递归地对子数组进行排序,最后将它们合并在一起。快速排序的时间复杂度为O(n*logn),空间复杂度为O(1)+O(n)。优点是时间复杂度最好,适用于大型数据集。缺点是最坏情况下时间复杂度为O(n2),不稳定且不适合小数据集。
该研究综述了视频异常检测中的“分而治之”策略,并提出了一种新方法,将人体骨架框架与视频数据分析技术相结合,实现了最先进的性能,超过了所有现有的先进方法。
分而治之是一种强大的算法范例,通过将复杂问题分解为更小的子问题来解决。分而治之的优势是可以产生高效的解决方案,并且可以并行化。然而,分而治之算法的递归性质会带来函数调用和内存使用的开销。
介绍ShardingSphere的配置方法,包括数据源配置、分片键配置、广播表配置等。应该先基于DDD思想划分业务单元,进行垂直分库,再针对增长量大的表进行水平分库。在分表维度上,应该优先考虑垂直分表的设计。
完成下面两步后,将自动完成登录并继续当前操作。