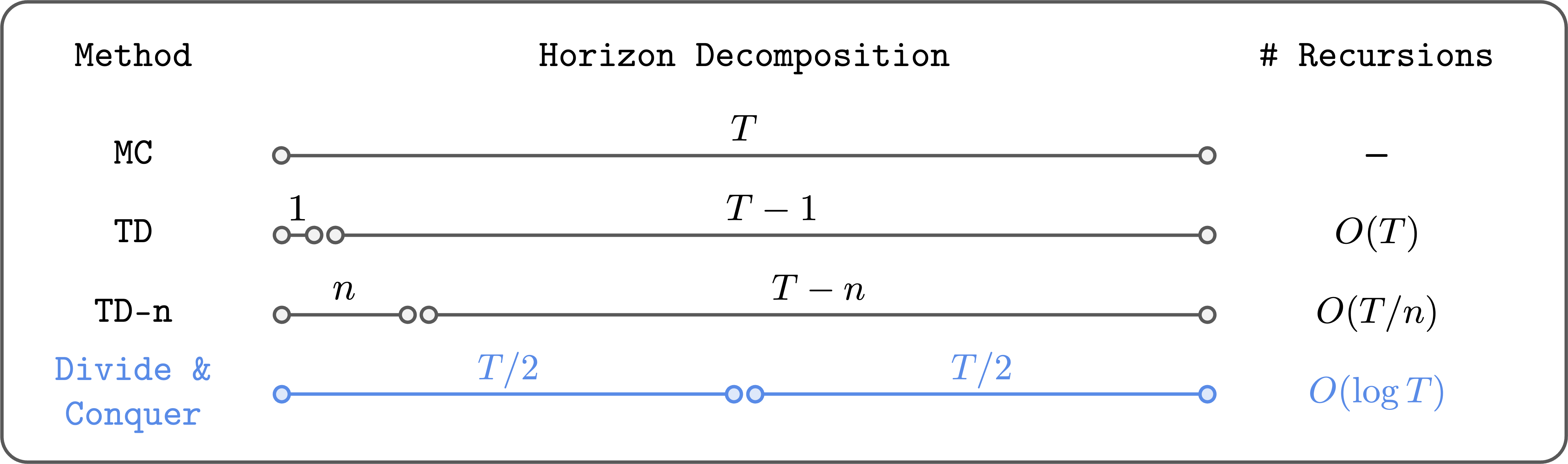
本文介绍了一种基于“分而治之”范式的强化学习算法,旨在解决传统时间差学习在长时间任务中的可扩展性问题。该算法采用离线策略强化学习,能够利用旧数据,适用于数据收集成本高的领域。通过将轨迹分为两个相等的部分,算法减少了贝尔曼递归的次数,从而降低了误差累积。最新的Transitive RL算法在复杂任务中表现优异,超越了许多传统方法,展示了分而治之在强化学习中的潜力。
完成下面两步后,将自动完成登录并继续当前操作。