生物黑客与AI医疗领域正在发展,智能体生物学将专注于数据分析,生物智能体需掌握数据解析以进行科学推理。随着分子数据的快速增长,数据分析将成为关键,智能体将在生物研究中成为重要协作者,而非完全替代科学家。
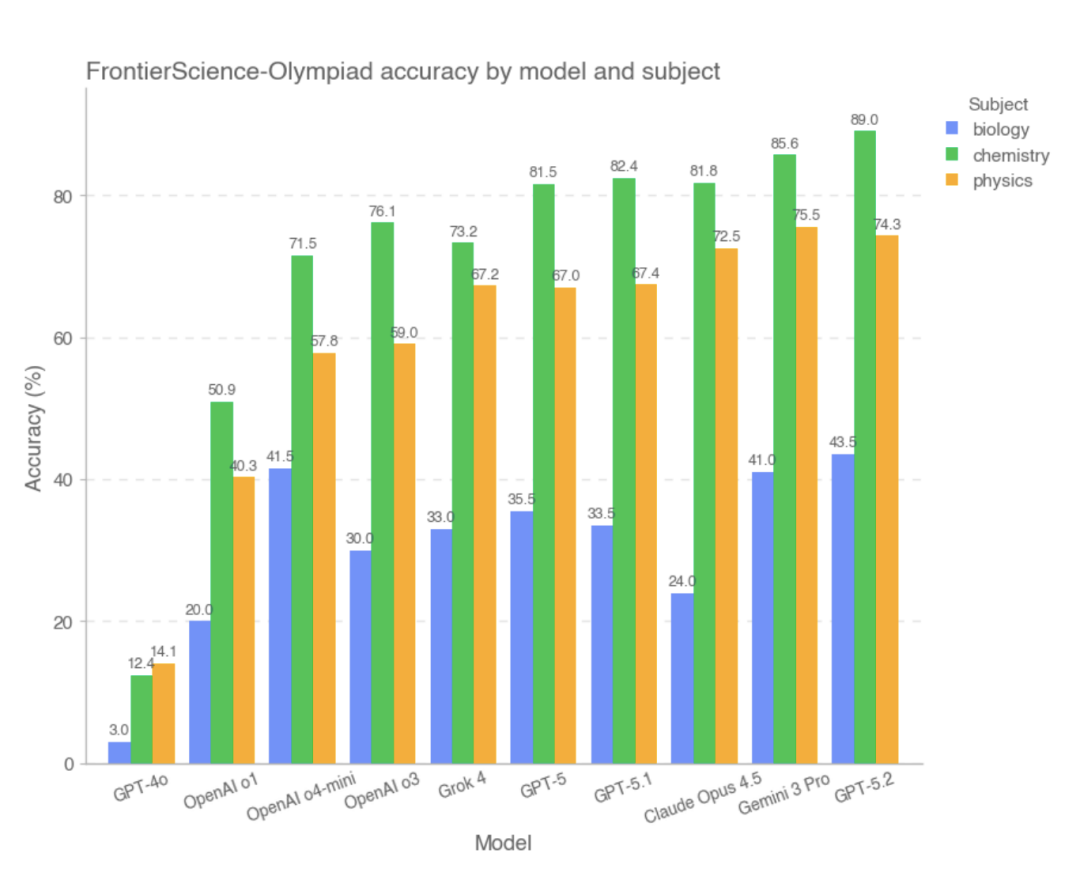
OpenAI推出FrontierScience基准测试,评估AI在科学推理和研究中的能力。GPT-5.2表现优异,但在复杂科研任务上仍有不足。该测试强调原创性和专家参与,为AI改进提供新参考。
Eigen-1系统在HLE测试中首次突破60分,Pass@1准确率为48.3%,Pass@5为61.74%。该系统基于开源DeepSeek V3.1,采用隐式知识增强、分层解决方案精炼和质量感知迭代推理三大创新机制,显著提升了AI的科学推理能力。
在信息过载和技术快速变革的时代,清晰思考和合理推理至关重要。本手册涵盖逻辑基础、软件开发、科学推理和批判性思维的实际应用,提供可靠的思维工具,适合学生和专业人士。内容包括逻辑理论、实际应用和哲学深度,旨在提升读者的逻辑思维能力。
本研究提出了多模态大型语言模型MatterChat,旨在解决无机材料性质理解与预测的挑战。该模型结合材料结构数据与文本信息,显著提升了材料性质预测性能,超越了通用模型如GPT-4,展现了在科学推理和材料合成中的潜在价值。
本研究提出了一种知识增强系统,结合知识图谱、问答对和大型语言模型,显著提升了钙钛矿太阳能电池领域的知识检索和科学推理效果,对研究人员的文献回顾和实验设计具有重要影响。
本研究提出了一个四阶段的研究路线图,旨在解决现有科学推理模型在跨领域泛化和多模态感知方面的不足,强调大规模语言模型在整合和推理不同数据类型中的能力,为实现人工通用智能提供新的视角。
本研究提出了SCP-116K数据集,包含116,756对高质量题-解,旨在解决高等教育科学领域缺乏优质数据集的问题。该数据集通过高效的自动提取管道,确保材料的科学性和教育水平,促进科学推理研究和高级科学推理任务的发展。
随着人工智能的发展,大语言模型在研究生级别科学推理中的能力受到关注。OpenAI的新模型o1在科学推理基准测试中表现出色。为评估中文大模型,推出了SuperCLUE-Science基准,涵盖物理、化学和生物等领域,旨在提供全面、客观和具有挑战性的评估,为未来模型开发提供参考。
阿里云通义团队于11月28日发布了开源AI推理模型QwQ-32B-Preview,该模型在数学和编程方面表现优异,具备研究生水平的科学推理能力,并在多个评测中取得高分,展现出深度自省能力。尽管存在一些局限性,开发者对其表现给予高度评价,认为这是开源领域的重要突破。
本文回顾并发展了科学哲学中的收敛主义,探讨如何根据趋向真理的能力评估推理方法,并分析了解释主义、工具主义和贝叶斯主义等理论。研究表明,收敛主义为科学推理提供了新的评估标准,具有重要理论价值。
本文介绍了通过引入可扩展工具集和开发SciAgent,提升大型语言模型(LLMs)在科学推理中的能力。构建了包含30,000个样本和6,000个工具的训练语料库,并通过SciToolBench基准测试验证了SciAgent的有效性,特别是SciAgent-Mistral-7B在准确率上优于其他同类模型。此外,提出了CACA Agent和ConAgents框架,增强了AI代理的规划能力和工具使用效率。
完成下面两步后,将自动完成登录并继续当前操作。