
GPT-5全面领先,OpenAI发布FrontierScience,「推理+科研」双轨检验大模型能力
内容提要
OpenAI推出FrontierScience基准测试,评估AI在科学推理和研究中的能力。GPT-5.2表现优异,但在复杂科研任务上仍有不足。该测试强调原创性和专家参与,为AI改进提供新参考。
关键要点
-
OpenAI推出FrontierScience基准测试,旨在评估AI在科学推理和研究中的能力。
-
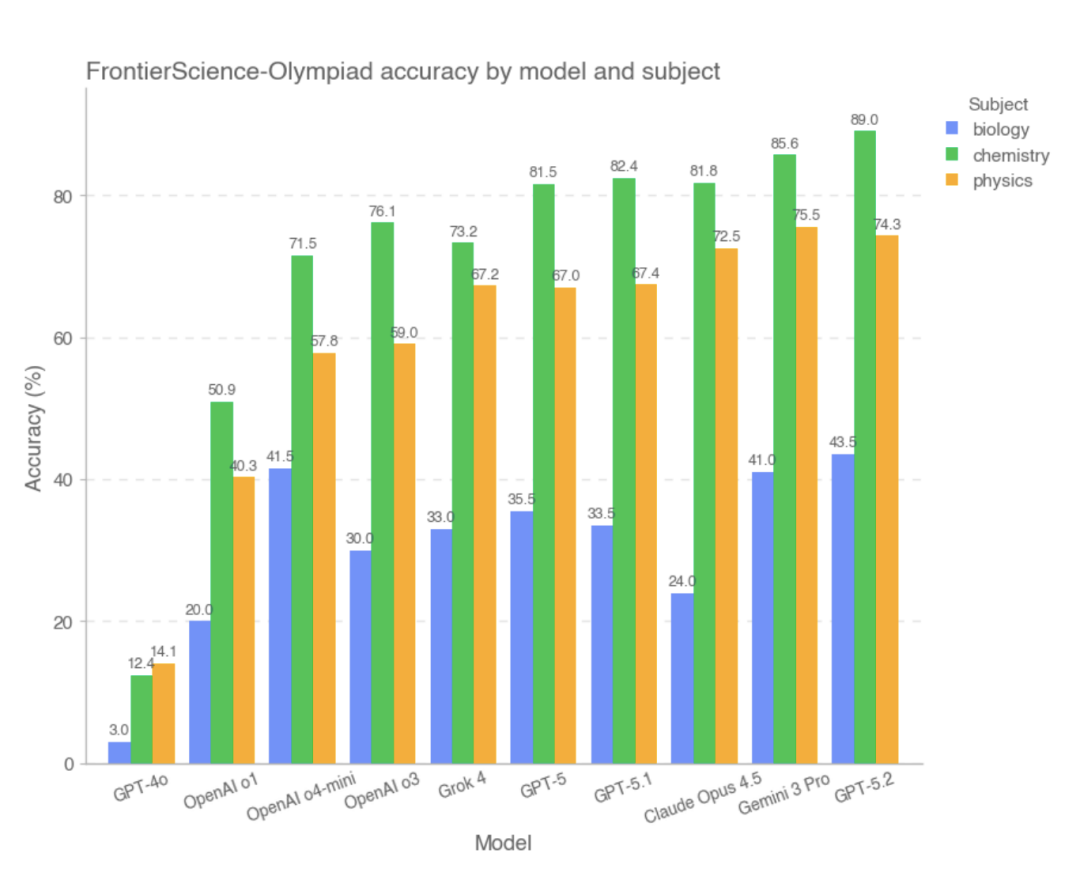
GPT-5.2在FrontierScience-Olympiad和Research任务中表现优异,但在复杂科研任务上仍有不足。
-
FrontierScience测试强调原创性和专家参与,提供了新的AI改进参考。
-
该基准测试由物理、化学和生物学领域的专家编写,包含奥林匹克题型和研究类题型。
-
FrontierScience-Research包含60道原创研究子任务,难度与博士科研过程相当。
-
OpenAI指出FrontierScience具有局限性,无法涵盖科学家日常工作的全部内容。
-
研究团队构建了FrontierScience评测数据集,用于系统性评估大模型在科学推理与科研子任务中的能力。
-
数据集分为Olympiad和Research两个子集,分别对应封闭式精确推理与开放式科研推理能力。
-
评测任务采用严格的评测流程和评分机制,确保模型输出仅基于内部知识和推理能力。
-
在Olympiad子集上,多数前沿模型得分较高,但在Research子集上表现明显偏低。
-
OpenAI强调FrontierScience为后续模型改进和科学智能研究提供了新的参照坐标。
延伸解读
FrontierScience的创新设计
FrontierScience基准测试由领域专家设计,结合了奥林匹克题型和研究类题型,旨在全面评估AI的科学推理和研究能力。这种双轨评估方式不仅关注模型的答案正确性,还强调推理过程的完整性,提供了更具挑战性的评测标准。
GPT-5.2的表现与局限
尽管GPT-5.2在Olympiad子集上表现优异,但在Research子集的复杂科研任务中仍显不足。这表明,尽管AI在封闭式推理中接近人类水平,但在开放式科研推理中仍需改进,尤其是在处理长链推理和复杂变量时。
FrontierScience的未来方向
OpenAI指出,FrontierScience的局限性在于无法涵盖科学家日常工作的所有维度。未来的基准测试需要更具挑战性和原创性,以推动AI在科研领域的应用。因此,FrontierScience为后续模型改进提供了新的参考框架,值得关注。
延伸问答
FrontierScience基准测试的主要目的是什么?
FrontierScience基准测试旨在评估AI在科学推理和研究中的能力。
GPT-5.2在FrontierScience测试中的表现如何?
GPT-5.2在FrontierScience-Olympiad和Research任务中分别得分25%和77%,表现优异。
FrontierScience测试的局限性是什么?
FrontierScience具有范围较窄的局限性,无法涵盖科学家日常工作的全部内容。
FrontierScience数据集是如何构建的?
FrontierScience数据集由专家原创设计,包含Olympiad和Research两个子集,旨在系统性评估大模型的能力。
FrontierScience-Olympiad和Research子集有什么区别?
Olympiad子集侧重封闭式精确推理,Research子集模拟真实科研过程,包含更开放的问题。
OpenAI对FrontierScience的未来发展有什么看法?
OpenAI认为FrontierScience为后续模型改进和科学智能研究提供了新的参照坐标,强调原创性和专家参与。
