从文章《线性注意力简史:从模仿、创新到反哺》我们可以发现,DeltaNet及其后的线性Attention模型,基本上都关联到了逆矩阵$(\boldsymbol{I} + \boldsymbol{...
本研究提出了一种新颖的多任务学习方法——多模态低秩专家混合(MMoLRE),有效解决了多模态情感分析与情绪识别中的参数冲突问题,提升了两者的表现。
线性代数在数据科学中至关重要,矩阵是数据的标准表示。矩阵的秩反映独立变量的数量,帮助识别数据中的独特信息。通过零空间和零度,可以揭示变量间的线性关系,这对机器学习算法至关重要。掌握这些概念是学习数据科学的基础。
TLoRA提出了一种新颖的三矩阵低秩适应方法,通过将权重更新分解为两个固定随机矩阵和一个可训练矩阵,实现高效的参数适应。研究表明,TLoRA在保持与现有低秩方法类似的性能同时,显著减少了可训练参数数量,体现了其在资源高效模型适应中的重要价值。
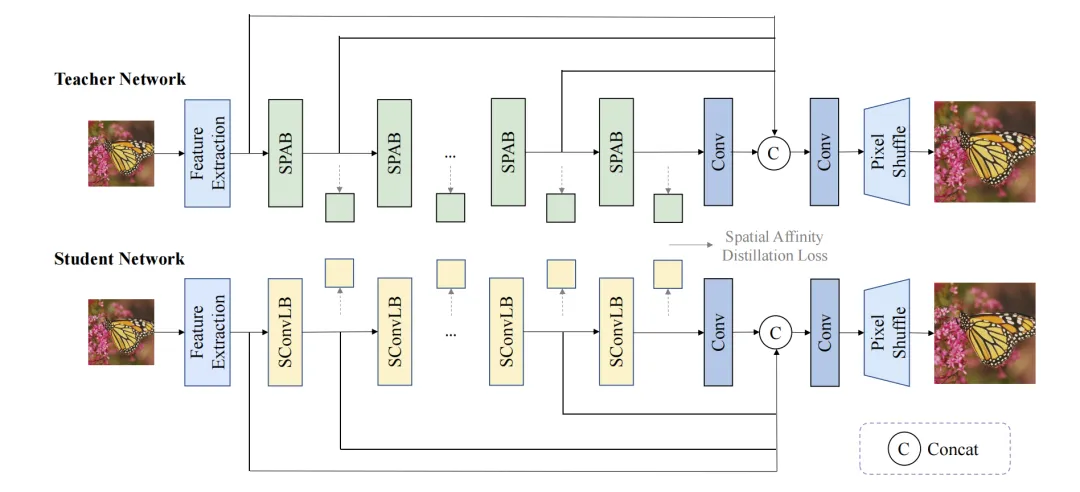
本文介绍了上海交通大学与传音团队合作的DSCLoRA模型,该模型在CVPR NTIRE 2025高效超分辨率挑战赛中获第一名。DSCLoRA结合低秩适应和知识蒸馏技术,显著提升超分辨率性能,且未增加计算成本。通过引入ConvLoRA,DSCLoRA在多个基准数据集上表现优异,展示了模型复杂度与性能的良好平衡。
本研究针对当前文本到图像合成中空间关系渲染不足的问题,提出了一种基于低秩适应的灵活微调框架ESPLoRA,利用从LAION-400M提取的空间显式提示数据集来提升生成模型的空间一致性。研究表明,所提出的方法在空间一致性基准测试中比现有最优框架CoMPaSS提高了13.33%的性能,显示出其在高质量图像生成中的显著潜力。
本研究解决了在少量标记样本下,视觉-语言模型的适应面临的严重过拟合和计算限制问题。提出的稀疏优化(SO)框架通过高稀疏性动态调整极少量参数,显著减轻了过拟合现象,并确保在低数据环境下稳定适应。在11个不同数据集上的广泛实验表明,SO在少样本适应性能上达到了最先进水平,并减少了内存开销。
本研究针对如何高效、准确地将大语言模型(LLMs)适应于专业科学领域(如材料科学)这一挑战进行了探讨,提出了一种结合结构化模型压缩和科学微调的两阶段框架。该框架通过局部低秩矩阵块的非周期性镶嵌与分块问答微调策略,实现了在数据稀缺条件下对LLMs的精确专业化,具有重要的应用前景。
本研究解决了传统RLHF框架假设人类偏好同质性的问题,导致个性化场景适应性不足。通过将低秩适应(LoRA)引入个性化RLHF框架,本研究提出了一种有效的学习个性化奖励模型的方法,能够在有限的本地数据集上进行训练。实验结果显示,该方法能有效捕捉人类偏好的共享和个体结构,提升个性化体验。
本研究提出了一种无训练的门控低秩适应方法(GLoCE),用于文本到图像扩散模型中的局部概念消除。该方法能够有效去除图像中的有害内容,同时保持其他区域不受影响。实验结果表明,GLoCE在生成图像的保真度、特异性和稳健性方面优于现有技术。
本研究针对RoPE基础模型中的KV缓存优化难题,提出了EliteKV框架,支持可变的KV缓存压缩比。通过RoPElite识别每个注意力头的内在频率偏好,并对关键维度进行选择性线性恢复,实现了高效的KV缓存压缩,实验结果表明,该方法在仅使用0.6%的原始训练数据进行最小调整的情况下,可以将KV缓存大小减少75%,并在性能上保持微小的差距。
本文针对现代自动语音识别模型在高计算强度下难以高效部署的问题,提出了LiteASR,一个用于ASR编码器的低秩压缩方案。此方法通过主成分分析(PCA)和优化自注意力机制,显著降低了推理成本,同时提高了转录准确性,显示出在效率和性能上的新平衡。
本研究提出的VesselSAM模型结合了Atrous Attention和低秩适应技术(LoRA),显著提高了主动脉血管分割的精度,整体DSC分数达到93.50%。该模型在多个医疗中心的测试中表现优异,为临床应用提供了新的方案。
本文探讨了加权低秩逼近问题,提出了一种新方法,能够在矩阵稠密情况下近乎线性时间内解决,显著提升计算效率,具有重要意义。
本研究提出了一种基于流形的随机梯度下降方法,解决了正则化的加权低秩逼近问题。实验结果显示,该算法在Netflix数据集上的表现优于传统方法,具有实际应用潜力。
本研究针对大规模语言模型(LLMs)微调过程中的低秩适应(LoRA)方法的收敛速度慢和计算开销大的问题,提出了一种新的Nyström方法,通过引入StructuredLoRA和NyströmLoRA优化初始化,从而提高效率和效果。此外,IntermediateTune方法专注于中间矩阵的微调,以进一步提升LLM的效率。研究结果表明,NLoRA在多个自然语言生成和理解任务上显著超越传统LoRA...
本研究解决了多智能体强化学习中的政策共享导致的代理专业化不足的问题。提出的低秩代理特定适应(LoRASA)方法通过将小型低秩适应矩阵附加到共享政策的每一层,促进了代理的个性化专业化和扩展性。实验结果显示,LoRASA在多个基准测试中表现优异,有望为多智能体强化学习的政策参数化树立新标准。
本研究解决了深度线性ResNet的最小范数权重问题,发现该架构的归纳偏差介于最小化核范数和秩之间。这表明,在适当的超参数下,深度非线性ResNet对最小化瓶颈秩具有归纳偏差,具有重要的理论意义和应用潜力。
本研究解决了现有低秩适应方法在稀疏大型语言模型上无法保持稀疏性的挑战。提出的LoRS方法通过权重重新计算和计算图重排策略,实现了在微调稀疏LLMs时的内存和计算效率,同时通过更好的适配器初始化提高了效果,显著降低了微调阶段的内存与计算消耗,且超越了现有的LoRA方法的性能。
本研究提出了一种新颖的三角自适应低秩适应框架(TriAdaptLoRA),旨在优化大语言模型微调中的参数分配,提高资源效率,超越现有方法。
完成下面两步后,将自动完成登录并继续当前操作。