BGE-M3是一款全能型嵌入模型,支持密集、稀疏和多向量检索,覆盖100多种语言,最大输入长度为8192词元。其量化版bge-m3-q8_0在GPUNexus平台上线,显存占用减少,推理速度提升,适合RAG系统和多语言知识库。2026年第三季度可免费试用。
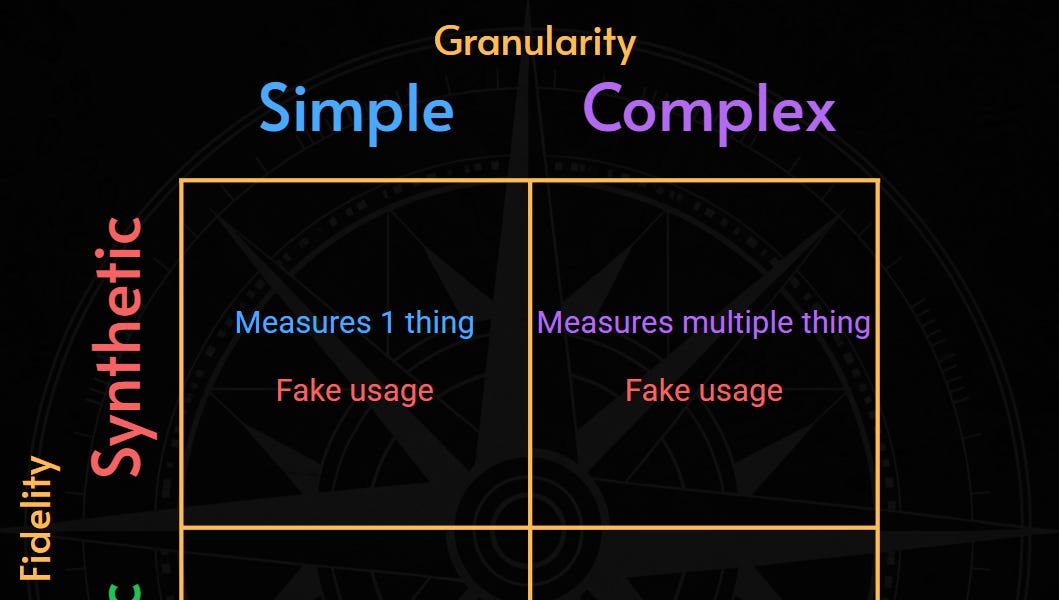
服务水平指标(SLI)是可靠性工程的重要概念,反映消费者对服务的看法。本文介绍了SLI Compass,一个二维模型,用于评估现有SLI的信噪比、成本和复杂性,并指导改进方向。常见的SLI包括可用性、延迟、成功率和效率。通过将SLI映射到二维坐标系,可以更好地理解和优化服务质量。
Boost的CMake集成新增B2风格的粒度,支持构建测试可执行文件、提取测试名称,并生成包含单独add_test条目的.cmake文件,通过TEST_INCLUDE_FILES实现独立报告和选择性运行。
本研究解决了现有推理代理在交互中存在的延迟与质量之间的权衡问题。提出的“群体思考”方法通过将单个大型语言模型转化为多个并发推理代理,使它们在令牌级别上动态协作,从而减少冗余推理并显著降低延迟。最重要的发现是该方法能有效利用闲置计算资源,尤其适用于小批量推理场景,提高生成质量和效率。
本文介绍了SMUGGLER,一种新型神经网络架构,能够高效且容错地进行字节级文本生成。与传统的基于标记的语言模型不同,SMUGGLER直接处理32位字符块,采用稀疏投票、质数多通道纠错和对抗训练等机制。实验结果表明,SMUGGLER在生成莎士比亚文本时,所需参数显著少于传统方法,并能在普通硬件上实现高质量生成。
本研究解决了现有反应舞蹈生成方法在处理局部信息和细粒度交互时的不足,提出了一种新的基于扩散的框架ReactDance,实现高保真度的长期连贯性和多尺度可控性。研究表明,ReactDance在运动语义控制和序列生成的准确性上优于现有方法,推动了舞蹈生成技术的进步。
该研究针对现有心电图分类方法在捕捉局部形态细节和长期时间依赖性方面的不足,提出了一种新颖的多粒度混合模型Cardioformer。该模型通过跨通道补丁、分层残差学习和双阶段自注意力机制,显著提高了心电图分析的准确性和鲁棒性,在多个基准数据集上表现优异,展示了其在心血管疾病诊断中的潜在影响。
本研究旨在解决传统计算机视觉任务无法有效识别图像中隐含意图的问题,提出了多粒度组合视觉线索学习(MCCL)方法,结合多种视觉特征进行意图识别。通过将意图识别视为多标签分类问题,采用图卷积网络来增强标签嵌入的相关性,显著提高了图像意图识别的准确性和可解释性,为理解复杂的人类表达形式奠定了基础。
本研究针对现有个性化新闻推荐方法只能通过单一用户资料无法充分捕捉用户兴趣多样性的问题,提出了一种多粒度候选关注的用户建模框架。该框架通过候选新闻编码和用户建模的组合,实现了对用户兴趣特征的综合表示,实验结果表明其表现显著优于基准模型。
在测试iOS应用时发现亮度调节粒度需为0.1,0.01无效。自iOS 10.3.3起,亮度调节粒度由0.01变为0.05,官方文档未说明此变更。
本研究针对现有多模态情感识别中单一对齐策略的限制,提出了一种多粒度跨模态对齐框架(MGCMA),以全面整合情感信息。通过分布式、实例化和基于标记的对齐模块,我们的方法在IEMOCAP数据集上的实验结果显示出显著优于当前最先进的技术,显示了其在情感表达复杂性处理中的潜在影响。
本研究通过整合细粒度概念注释,提升了多模态大型语言模型在视觉-语言任务中的性能,并推出了新数据集MMGiC,实验结果显示模型表现显著提高。
本研究解决了视觉文本不一致性评估在清洗视觉语言数据中的重要性,以往方法难以应对图像描述数据集中的多样性和不一致性。提出的HMGIE框架通过构建语义图,实现了对图像-描述对的多粒度评估,并在实验中展示了在不同数据集上的优越性能。
本研究提出了一种新颖的多模态、多粒度路径表示学习框架(MM-Path),旨在提升智能交通领域中路径表示的有效性。通过多粒度对齐策略和跨模态残差融合组件,MM-Path有效整合了道路网络与图像数据的特征,实验结果显示该方法在路径表示学习中具有重要潜力。
本文提出了一种优化框架,用于生成信息性和主题连贯性更强的时间线摘要。研究介绍了多种时间线摘要生成方法及评估指标,创建了DiverseSumm数据集以应对多样信息摘要的挑战,并分析了大型语言模型在此任务中的表现。实验结果表明,背景摘要机制和合适的模型在处理复杂事件时效果显著,为多语言新闻摘要任务提供了新思路。
本文介绍了GRank图模式实体排名模型,并评估其在链接预测任务中的表现,结果优于ComplEx和TorusE。研究还探讨了知识图谱的结构学习、补全及质量评估,提出了改进评估方法的建议,强调了知识图谱在各领域的应用潜力。
本研究解决了现有图形用户界面(GUI)任务训练数据不足的问题。我们提出了EDGE,一个通用的数据合成框架,能够从网页自动生成大规模多粒度的训练数据,显著提升了大型视觉语言模型(LVLMs)对网页的理解能力。实验证明,该方法大幅降低了对手动标注的依赖,能够将所生成的数据迁移到新的桌面和移动环境中,推动相关研究的进展。
Kosmos-G模型利用多模态大型语言模型(MLLMs)的视觉感知能力生成多图像的视觉-语言输入。为提高感知准确性,提出了VCoder工具,并创建了COST数据集用于训练和评估。研究表明,VCoder在对象感知能力上优于其他模型。本文还回顾了MLLMs的架构、对齐策略和训练技术,分析了其在视觉理解任务上的表现,为未来研究奠定基础。
本研究提出了MTU-Bench,一个多粒度工具使用基准,解决了现有工具在评估场景和成本上的不足。它涵盖五种工具使用场景,采用基于预测和实际结果的评估指标,降低评估成本。实验表明,MTU-Bench有效提升了大型语言模型的工具使用能力。
MapTR是一个高效的在线矢量高清地图构建系统,采用点集建模和层次查询方案,提升自动驾驶系统的规划性能。研究提出了Map Transformer框架,利用统一排列建模和层次匹配,实时处理复杂地图元素,表现优异。InsightMapper方法在NuScenes数据集上超越现有技术,提升拓扑正确性。新型Mask2Map方法通过实例级Mask和地图预测网络协作,进一步提高地图构建精度。
完成下面两步后,将自动完成登录并继续当前操作。