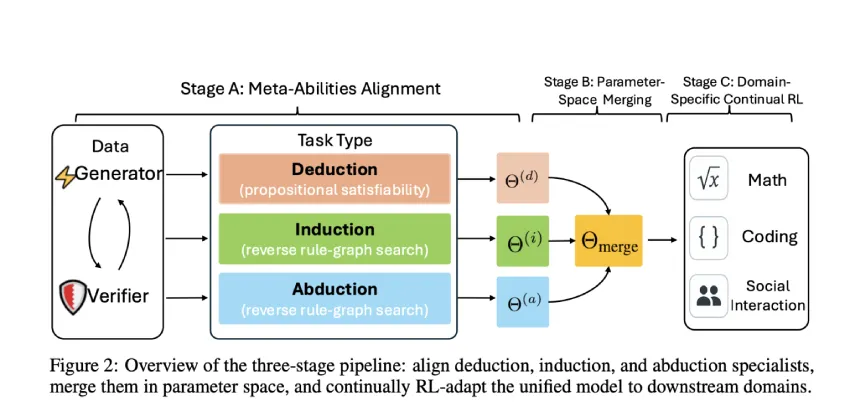
大型推理模型(LRM)通过结构化强化学习提升推理能力,克服了依赖“顿悟时刻”的局限性。研究者提出了结合演绎、归纳和溯因推理的三阶段流程,显著提高了模型在数学和编程任务中的表现。
本文研究了结构化强化学习在协同行为中的应用,建立了模型并为表格设置中的协同行为建立了值函数后悔边界。同时,推广和扩展了自然策略梯度分析,并给出了关于样本复杂度的期望和高概率的见解。最后,进行了一个随机匹配玩具模型的模拟。
完成下面两步后,将自动完成登录并继续当前操作。