
超越顿悟时刻:在大型语言模型中构建推理
内容提要
大型推理模型(LRM)通过结构化强化学习提升推理能力,克服了依赖“顿悟时刻”的局限性。研究者提出了结合演绎、归纳和溯因推理的三阶段流程,显著提高了模型在数学和编程任务中的表现。
关键要点
-
大型推理模型(LRM)通过结构化强化学习提升推理能力,克服了依赖“顿悟时刻”的局限性。
-
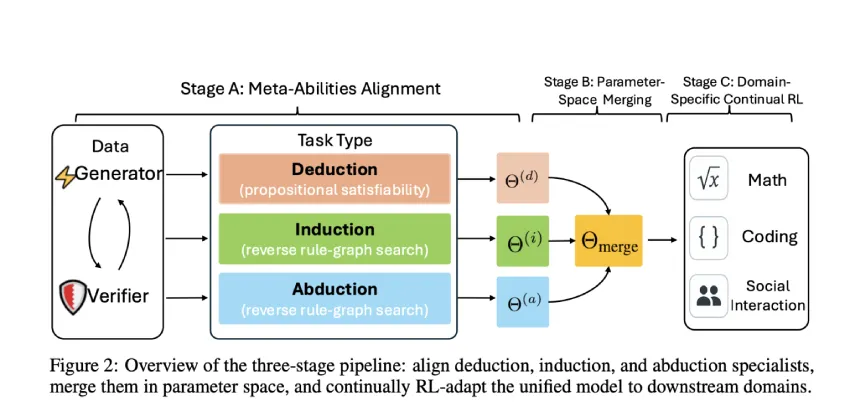
研究者提出了结合演绎、归纳和溯因推理的三阶段流程,显著提高了模型在数学和编程任务中的表现。
-
DeepSeek-R1等模型通过精心设计的强化学习流程,诱导反思性推理能力,但自发行为难以预测且不一致。
-
研究人员探索了针对特定推理类型的结构化强化学习框架,包括对齐专家模型和持续强化学习。
-
使用规则调节的强化学习工具Logic-RL提高了在逻辑难题中的可迁移性。
-
新加坡国立大学、清华大学和Salesforce AI Research的研究人员通过三阶段流程显著提升了模型性能。
-
该研究设计了与演绎、归纳和溯因推理相一致的任务,并通过结构化奖励独立训练模型。
-
合并模型在诊断任务上的表现比指令调优的基线模型高出10%以上,且在实际基准测试中高出2%。
-
模块化、系统化的训练方法为构建可靠、可解释的推理系统提供了可扩展且可控的基础。
延伸解读
推理模型的演变
大型推理模型(LRM)通过结构化强化学习的方式,逐步克服了传统依赖“顿悟时刻”的局限性。这一转变不仅提升了模型的推理能力,也为未来的人工智能系统提供了更为可靠的基础。研究者们的三阶段流程展示了如何通过系统化的方法来增强模型的表现,尤其是在复杂的数学和编程任务中。
结构化强化学习的优势
研究中提出的结构化强化学习框架,结合了演绎、归纳和溯因推理,显著提高了模型的可迁移性和准确性。这种方法不仅提升了模型在特定任务上的表现,还为不同领域的应用提供了可扩展的解决方案。读者在关注新技术时,应考虑这些方法在实际应用中的潜力与局限性。
模型合并的效果
通过对齐专家模型和参数空间合并,研究者们成功提升了模型的整体性能。这种合并策略在诊断任务中表现出色,超越了传统的指令调优方法。对于希望在特定领域内提升推理能力的研究者而言,理解这种合并机制的细节将是关键。
延伸问答
大型推理模型(LRM)是如何提升推理能力的?
大型推理模型通过结构化强化学习提升推理能力,克服了依赖“顿悟时刻”的局限性。
研究者提出了什么样的推理流程来提高模型表现?
研究者提出了结合演绎、归纳和溯因推理的三阶段流程,显著提高了模型在数学和编程任务中的表现。
DeepSeek-R1模型的特点是什么?
DeepSeek-R1模型通过精心设计的强化学习流程诱导反思性推理能力,但其自发行为难以预测且不一致。
如何提高模型在逻辑难题中的表现?
使用规则调节的强化学习工具Logic-RL可以提高模型在逻辑难题中的可迁移性。
该研究的主要贡献是什么?
该研究通过将大型语言模型与演绎、归纳和溯因推理对齐,提出了可扩展的训练方法,显著提升了模型性能。
合并模型在诊断任务中的表现如何?
合并模型在诊断任务上的表现比指令调优的基线模型高出10%以上,且在实际基准测试中高出2%。
