


TASER:通过系统评估和推理进行翻译质量评估
Apple Machine Learning Research
·
思维的幻觉:通过问题复杂性视角理解推理模型的优势与局限性
Apple Machine Learning Research
·

苹果的《思维的幻觉》论文探讨大型推理模型的局限性
InfoQ
·

追求人工智能自主性忽视了短期代理收益
The New Stack
·
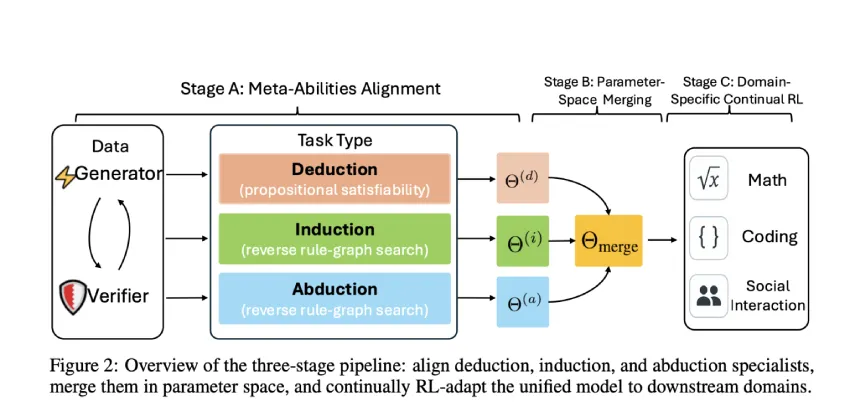
超越顿悟时刻:在大型语言模型中构建推理
实时互动网
·

250多篇论文,上海AI Lab综述推理大模型高效思考
机器之心
·

