


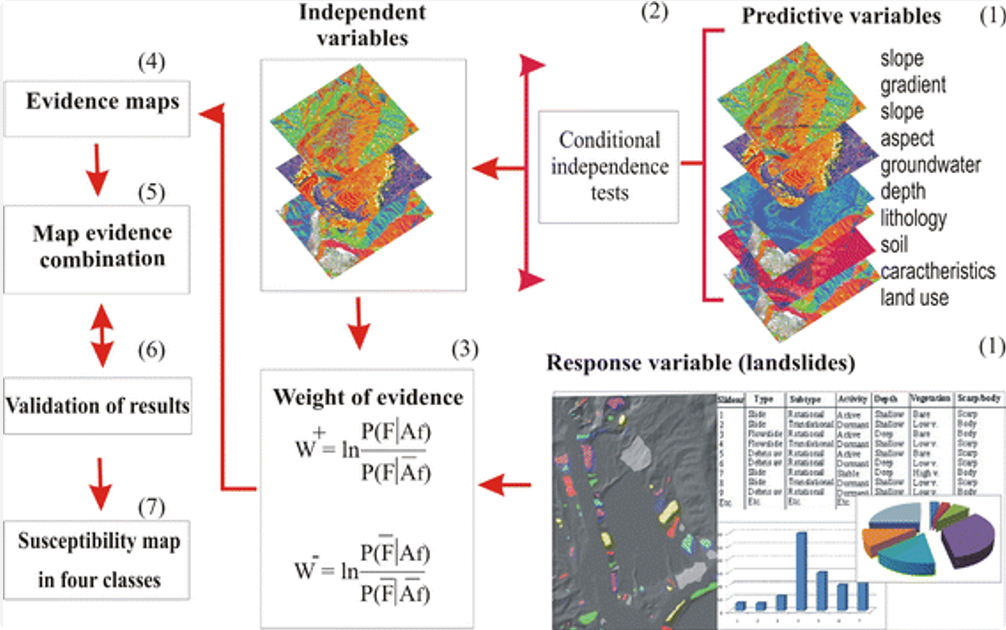
大数据成矿预测系列(一) | 经典模型“证据权重法”的前世今生
Seraphineの小窝
·


TimescaleDB 的救星 - 加速统计分析
Timescale Blog
·




如何验证任何(合理的)分布特性:分布的计算上可靠的论证系统
Apple Machine Learning Research
·

什么是SAS?
DEV Community
·

Megastat作业帮助:统计成功的一站式解决方案
DEV Community
·
