本文介绍了Pandas库中DataFrame.map()函数的用法,替代了已弃用的applymap()。该函数可以对DataFrame中的每个元素应用自定义函数,处理缺失值,并支持链式操作。示例包括温度转换、字典映射和缺失值处理,展示了高效的数据预处理方法。
数据转换和特征工程是机器学习的关键步骤。AWS提供了SageMaker Data Wrangler和Glue等高效工具,简化数据准备过程。文章讨论了数据清洗、缺失值处理、去重和特征工程等技术,强调了使用AWS工具提升数据处理效率和质量的重要性。
本研究提出TRACE方法,通过自注意力机制优化临床风险评估的数据处理,增强特征交互和结果解读能力,特别在解释性和缺失值处理上表现突出。
本研究提出了一种新的疾病诊断建模方法,基于异构信息网络,能够处理缺失值和异构数据,实现更准确的疾病诊断。实验结果显示该方法在诊断编码、疾病预测和临床事件相似性方面优于基准模型。
本文介绍了数据预处理中的数据清洗方法,包括缺失值处理、重复值处理和异常值处理。对于缺失值,可以使用dropna()删除缺失数据,或使用fillna()填充缺失值。对于重复值,可以使用duplicated()判断重复值,然后使用drop_duplicates()去除重复值。对于异常值,可以使用箱形图来识别异常数据。文章还提到了数据预处理在信用卡欺诈检测、网络入侵检测和公共卫生安全等领域的应用。
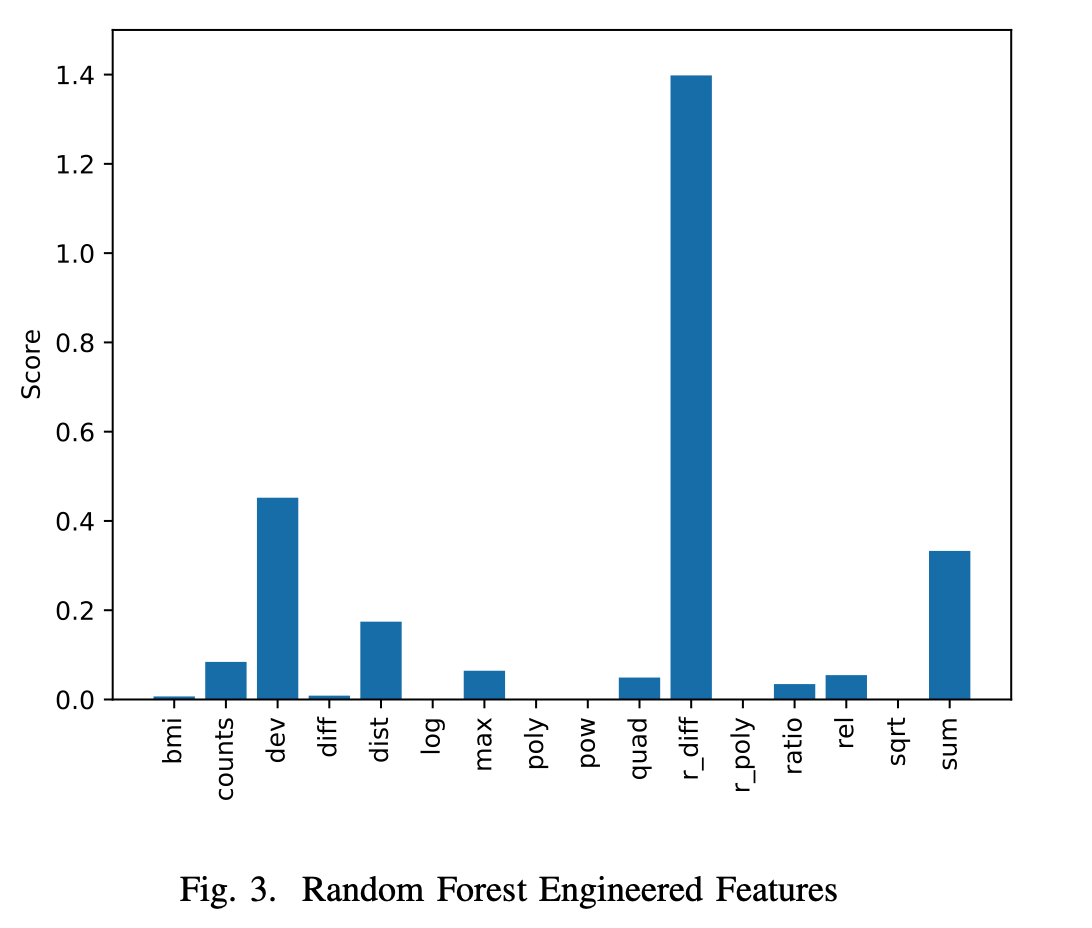
文章讨论了数据清洗、特征构建和特征选择的技术。缺失值处理包括填充和无效值识别。特征构建涉及单特征处理、特征组合和扩散,并比较了DNN、SVR、RF和GBM等模型的表现。特征选择方法包括过滤法、包装法和嵌入法,强调模型的稳定性和解释性。
完成下面两步后,将自动完成登录并继续当前操作。