
特征工程
内容提要
文章讨论了数据清洗、特征构建和特征选择的技术。缺失值处理包括填充和无效值识别。特征构建涉及单特征处理、特征组合和扩散,并比较了DNN、SVR、RF和GBM等模型的表现。特征选择方法包括过滤法、包装法和嵌入法,强调模型的稳定性和解释性。
关键要点
-
数据清洗包括缺失值处理和无效值识别。
-
缺失值处理方法有填充0、均值和中位数。
-
无效值的识别包括只有一个取值和无区分度的特征。
-
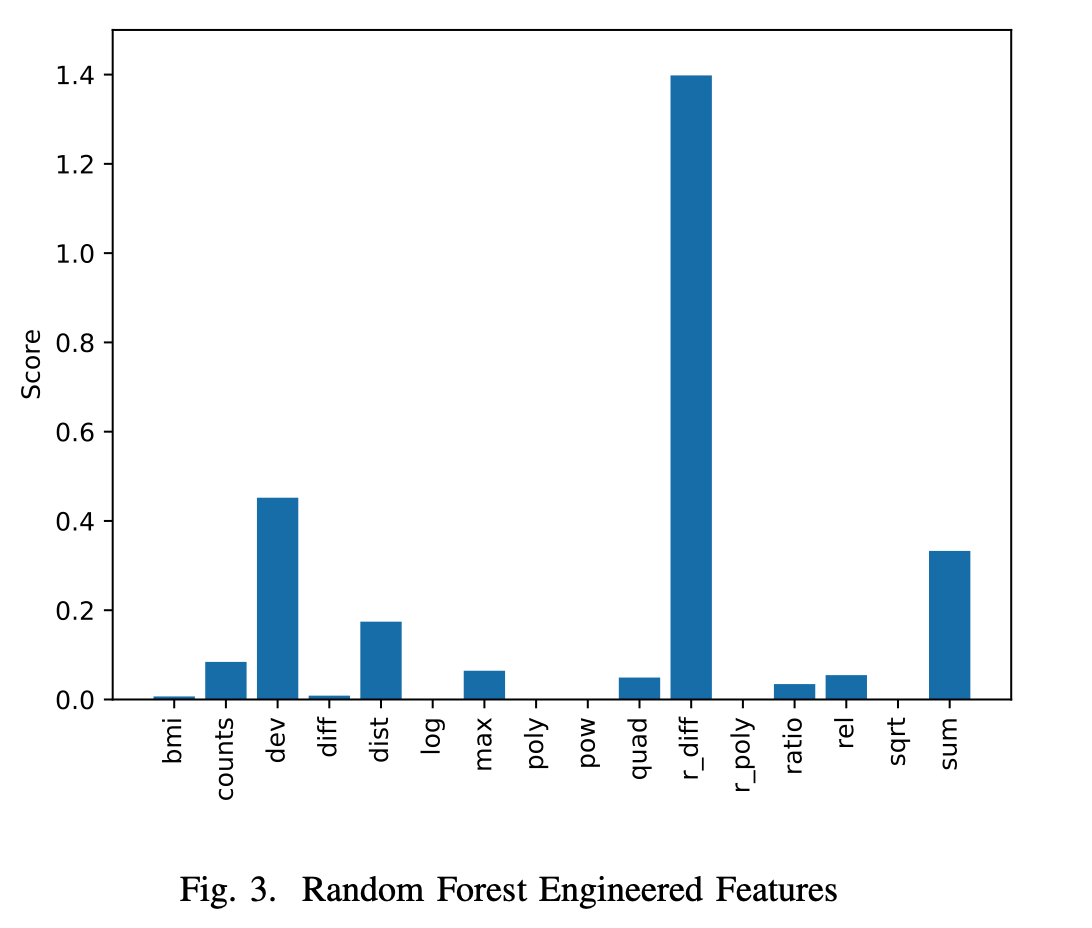
特征构建包括单特征处理、特征组合和特征扩散。
-
单特征处理方法有label encoder、oneHot encoder和target encoder。
-
特征组合方法包括统计特征和多项式特征。
-
不同模型(DNN、SVR、RF、GBM)在特征构建上的表现不同。
-
DNN在特征构建能力上表现最好,SVR表现最差。
-
特征选择方法包括过滤法、包装法和嵌入法。
-
过滤法通过IV值评估单特征的区分度。
-
包装法通过特征的加入和删除观察模型指标变化。
-
嵌入法关注特征权重,并考虑引入正则化。
-
特征相关性分析方法包括主成分分析、相似度和聚类。
延伸解读
数据清洗的重要性
数据清洗是特征工程的基础,缺失值和无效值的处理直接影响模型的性能。选择合适的填充方法(如均值或中位数)可以提高数据的质量,确保后续特征构建的有效性。
特征构建的多样性
特征构建方法多种多样,包括单特征处理和特征组合。不同模型对特征的敏感度不同,DNN在特征构建上表现优异,而SVR则相对较弱。了解这些差异有助于选择合适的模型和特征。
特征选择方法的比较
特征选择是提升模型性能的关键步骤。过滤法、包装法和嵌入法各有优缺点,选择合适的方法可以提高模型的稳定性和解释性。特别是在高维数据中,合理的特征选择尤为重要。
延伸问答
数据清洗的主要步骤有哪些?
数据清洗主要包括缺失值处理和无效值识别。
缺失值处理有哪些常用方法?
常用的缺失值处理方法有填充0、均值和中位数。
特征构建的主要方法是什么?
特征构建主要包括单特征处理、特征组合和特征扩散。
不同模型在特征构建上的表现如何?
DNN在特征构建能力上表现最好,SVR表现最差,RF和GBM表现相似。
特征选择的方法有哪些?
特征选择的方法包括过滤法、包装法和嵌入法。
过滤法在特征选择中如何评估特征?
过滤法通过IV值评估单特征的区分度。
