
全身条件自我中心视频预测
The Berkeley Artificial Intelligence Research Blog
·

EgoDex:从大规模自我中心视频中学习灵巧操作
Apple Machine Learning Research
·
利用多模态大语言模型推进自我中心视频问答
Apple Machine Learning Research
·
MM-Ego:构建自我中心多模态大语言模型的探索
Apple Machine Learning Research
·
ARMOR:人形机器人碰撞避免与运动规划的自我中心感知
Apple Machine Learning Research
·
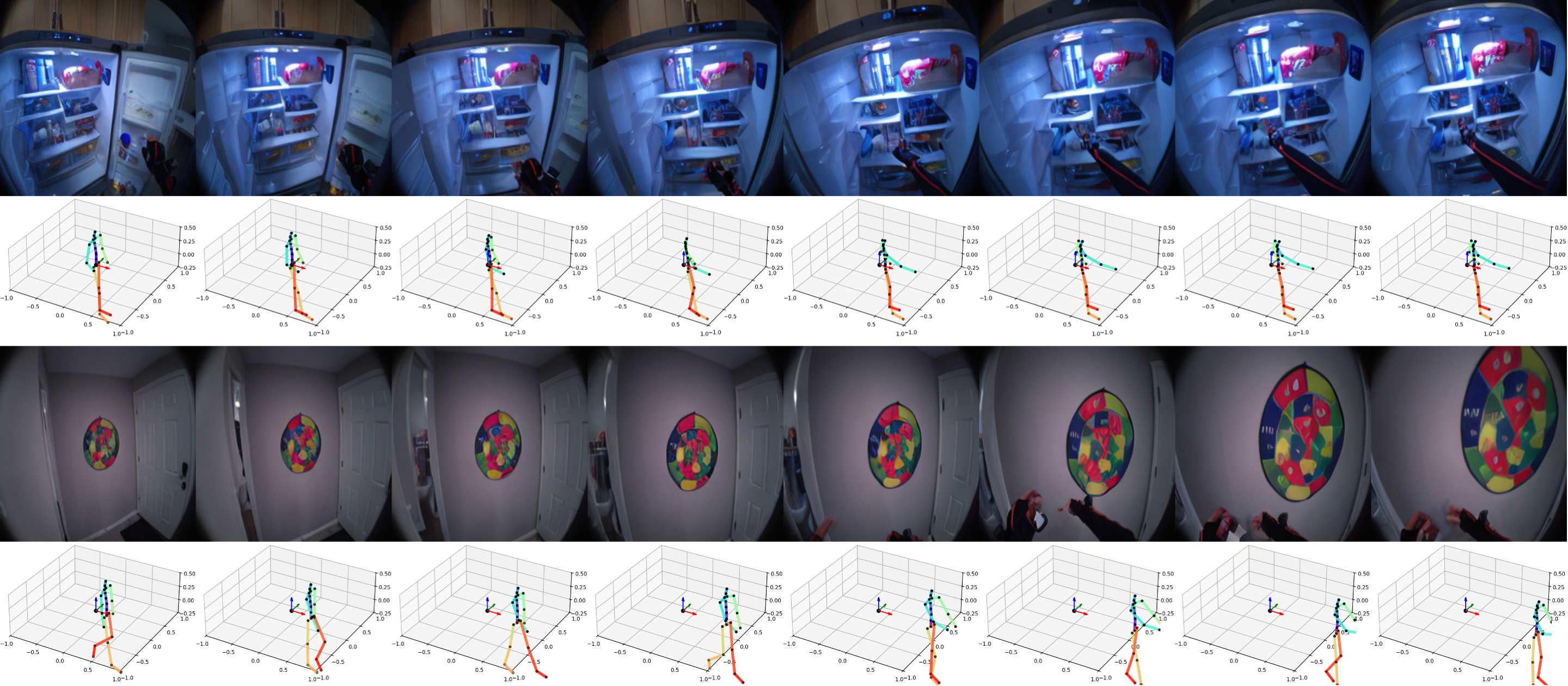
从双重稀疏的自我中心视频数据中估计自我身体姿态
BriefGPT - AI 论文速递
·

