
全身条件自我中心视频预测
内容提要
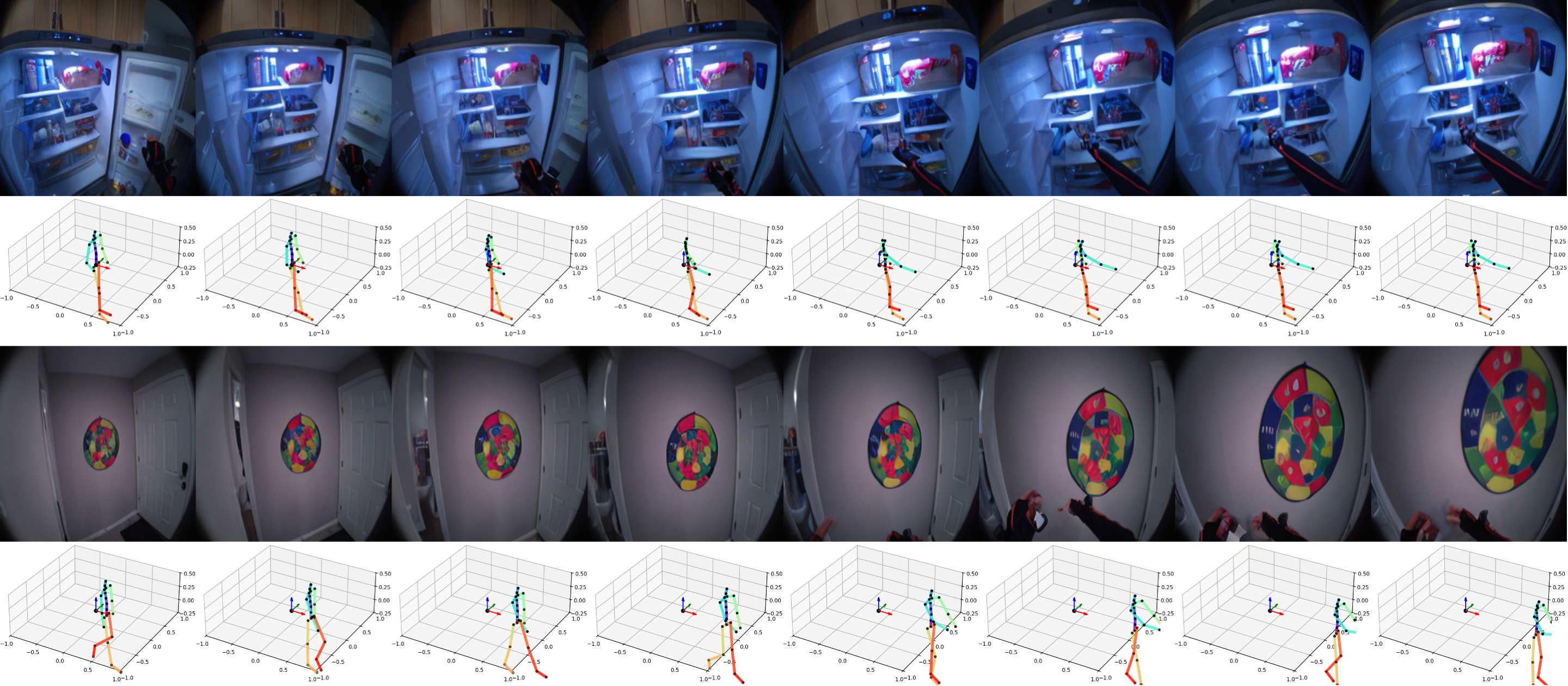
本文介绍了一种名为PEVA的模型,该模型通过学习身体关节的运动轨迹来预测自我中心视频,能够生成复杂的动作视频并支持长时间预测。PEVA在真实场景中表现优异,能够模拟人类的目标导向行为,但在规划和任务意图理解方面仍存在局限。未来研究将着重提升模型的互动性和任务导向能力。
关键要点
-
PEVA模型通过学习身体关节的运动轨迹来预测自我中心视频,能够生成复杂的动作视频并支持长时间预测。
-
PEVA在真实场景中表现优异,能够模拟人类的目标导向行为。
-
模型在规划和任务意图理解方面仍存在局限,未来研究将着重提升模型的互动性和任务导向能力。
-
PEVA使用自回归条件扩散变换器,能够处理高维度、时间延续和物理约束的人类动作。
-
模型通过分解复杂的人类运动为原子动作,测试模型对特定关节运动如何影响自我中心视图的理解。
-
PEVA在生成高质量自我中心视频方面表现优于基线模型,并在长时间范围内保持一致性。
-
未来的研究方向包括扩展PEVA到闭环控制或互动环境,并结合高层目标条件和物体中心表示。
延伸解读
PEVA模型的应用潜力
PEVA模型在生成自我中心视频方面表现出色,能够模拟复杂的人类动作。这一能力不仅适用于娱乐和游戏领域,还可以在机器人技术和虚拟现实中实现更自然的交互体验。随着技术的进步,PEVA有潜力在教育和训练模拟中发挥重要作用,帮助用户更好地理解和掌握动作技能。
模型的局限性与未来方向
尽管PEVA在视频生成方面表现优异,但在规划和任务意图理解上仍存在不足。未来的研究需要关注如何增强模型的互动性和任务导向能力,以便更好地适应复杂的现实场景。此外,结合高层目标条件和物体中心表示将是提升模型性能的关键方向。
高维度动作表示的重要性
PEVA通过高维度的动作表示来捕捉人类运动的复杂性,这使得模型能够更准确地理解和预测动作对环境的影响。这种方法不仅提高了视频生成的质量,也为未来的研究提供了新的思路,尤其是在处理多样化的动作和环境时,能够更好地反映人类的真实行为。
延伸问答
PEVA模型的主要功能是什么?
PEVA模型通过学习身体关节的运动轨迹来预测自我中心视频,能够生成复杂的动作视频并支持长时间预测。
PEVA在真实场景中的表现如何?
PEVA在真实场景中表现优异,能够模拟人类的目标导向行为。
PEVA模型的局限性是什么?
PEVA在规划和任务意图理解方面仍存在局限,未来研究将着重提升模型的互动性和任务导向能力。
PEVA如何处理高维度的人类动作?
PEVA使用自回归条件扩散变换器,能够处理高维度、时间延续和物理约束的人类动作。
PEVA模型如何生成高质量的视频?
PEVA通过分解复杂的人类运动为原子动作,测试模型对特定关节运动如何影响自我中心视图的理解,从而生成高质量视频。
未来对PEVA模型的研究方向是什么?
未来的研究方向包括扩展PEVA到闭环控制或互动环境,并结合高层目标条件和物体中心表示。
