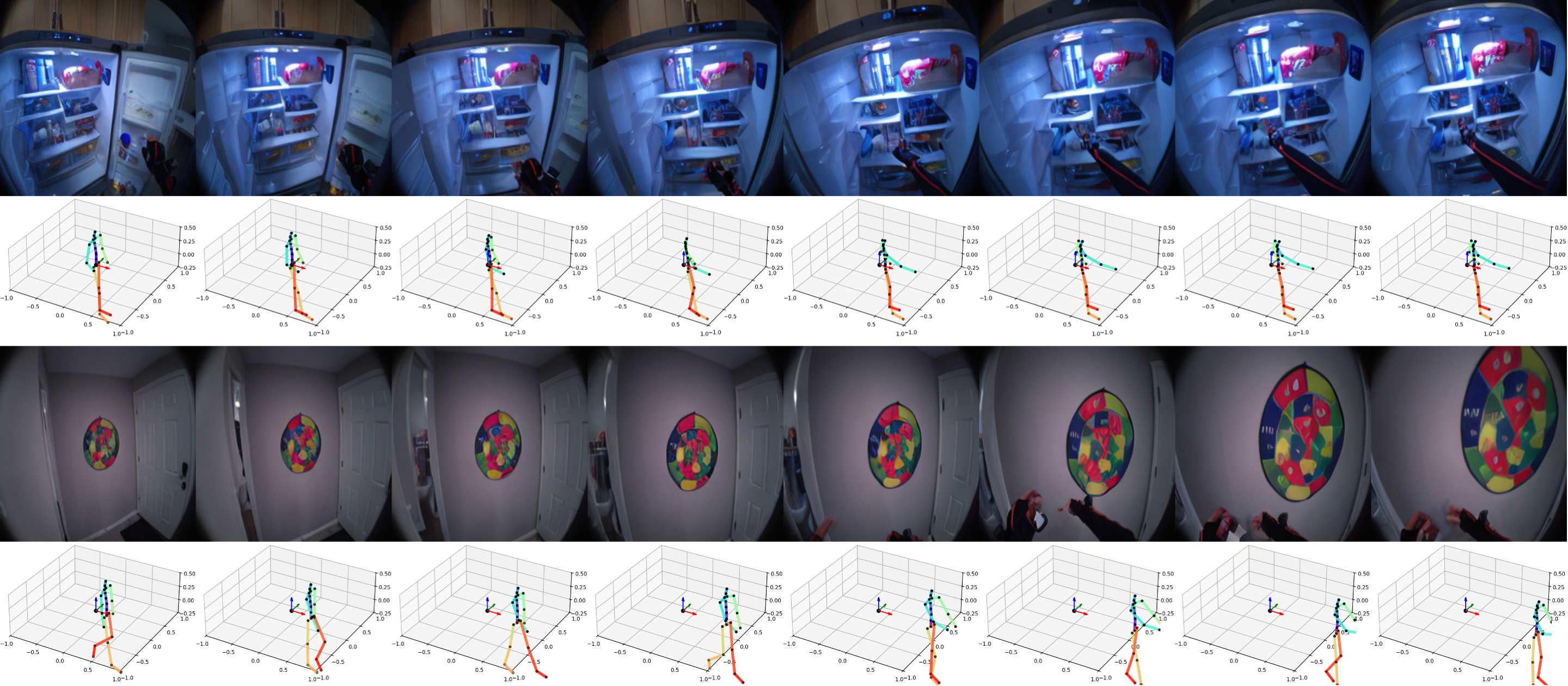
本文介绍了一种名为PEVA的模型,该模型通过学习身体关节的运动轨迹来预测自我中心视频,能够生成复杂的动作视频并支持长时间预测。PEVA在真实场景中表现优异,能够模拟人类的目标导向行为,但在规划和任务意图理解方面仍存在局限。未来研究将着重提升模型的互动性和任务导向能力。
本研究构建了多模态基础模型以理解自我中心视频,自动生成了700万高质量问答样本,并建立了629个视频和7026个问题的基准,以评估模型识别视觉细节的能力。提出了一种新颖的“记忆指针提示”机制,以提高模型对视频内容的理解效率。
本研究推出EgoVid-5M数据集,包含500万段自我中心视频及详细动作注释,旨在提升视频生成效果,推动虚拟现实等应用领域的发展。
本研究提出SEE-ME框架,旨在解决自我中心视频中佩戴者的3D姿态估计问题。通过结合概率扩散模型和互动信息,SEE-ME在姿态估计误差上比现有技术提高了53%。
本研究提出了AMEGO方法,用于改善自我中心视频的理解。该方法通过构建自包含表征来捕捉关键位置和对象交互,并实现了对视频的多重查询。实验结果显示AMEGO在新引入的主动记忆基准上表现优异。
本研究提出了一种新的方法,通过结合场景几何、物体中心跟踪和实例分割,解决了自我中心视频中的3D场景理解挑战。实验结果表明,该方法在跟踪和分割一致性指标上优于现有的二维方法。
本文介绍了一个新的像素注释数据集VISOR,用于在自我中心视频中分割手和活动对象。该数据集包含272K带标注的语义掩模,9.9M插值稠密掩模,67K手-物体关系,覆盖36小时的179个未修剪的视频。同时,还介绍了三项有关视频对象分割、交互理解和长期推理的挑战。
该研究使用数据驱动先验恢复物体形状的神经3D表示和时间变化的动作和手关节。在6个物体类别的自我中心视频上进行实证评估,相较于先前的方法有显著改进。该系统能够从YouTube中重建任意剪辑,展示了第一人称和第三人称的交互。
本文介绍了一种面向对象的解码器,通过预测手部位置、物体位置和物体的语义标签来增强模型的对象感知能力,提高自我中心视频的时空表示性能。实验证明,该模型学到的对象感知表示在视频文本检索和分类任务中的性能优于现有技术水平,即使与使用更大批次大小进行训练的网络相比也是如此。通过使用嘈杂的图像级别检测作为伪标签进行训练,模型可以提供更好的边界框,并在关联文本描述中进行词的定位,从而通过视觉文本对齐来提高自我中心视频模型的性能。
完成下面两步后,将自动完成登录并继续当前操作。