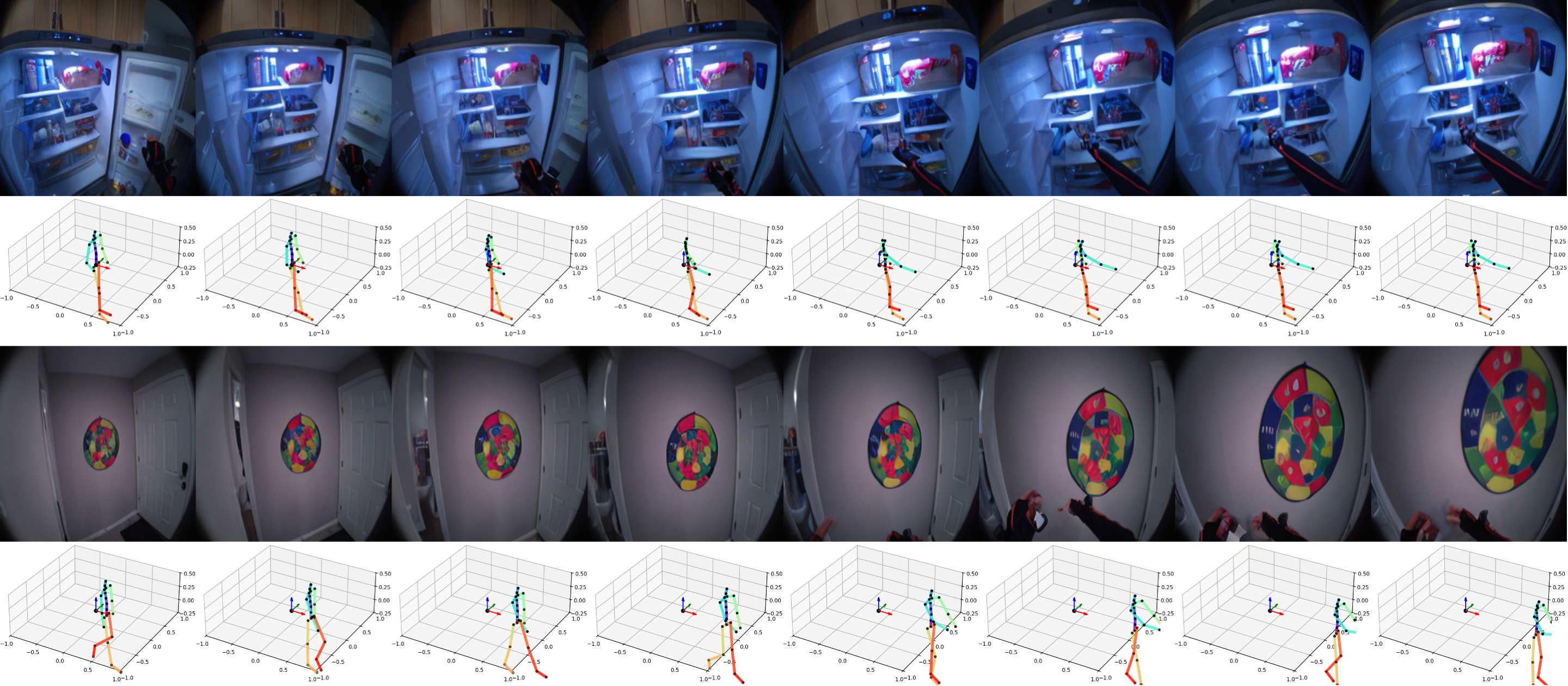
本文介绍了一种名为PEVA的模型,该模型通过学习身体关节的运动轨迹来预测自我中心视频,能够生成复杂的动作视频并支持长时间预测。PEVA在真实场景中表现优异,能够模拟人类的目标导向行为,但在规划和任务意图理解方面仍存在局限。未来研究将着重提升模型的互动性和任务导向能力。
本研究探讨了婴儿在没有外部奖励时如何表现出目标导向行为,提出了“自我先验”模型。研究表明,该机制能够基于自身感官体验自发产生意图行为,促进早期探索与学习。
完成下面两步后,将自动完成登录并继续当前操作。