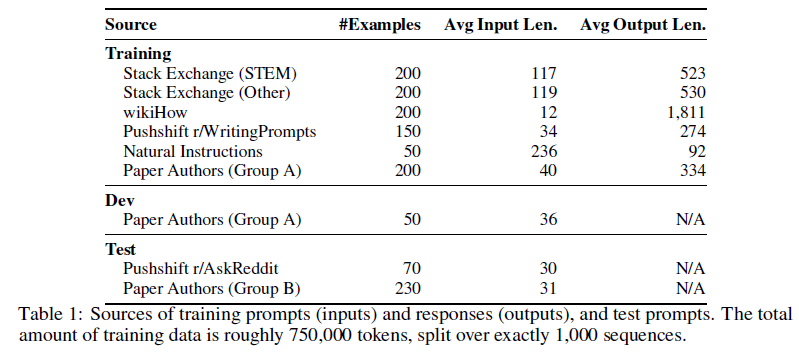
LIMA是一篇网红文,用SFT方案训练了一个模型,证实了表面对齐假设。该模型只用了1000条指令微调数据,但效果超过了使用52000条数据的Alpaca模型。LIMA验证了绝大部分的知识是在预训练阶段习得的,一定程度上也说明了有效的SFT甚至可以超越RLHF的结果。
该研究介绍了LIMA模型的开发和性能评估,该模型通过训练LLaMA的650亿参数版本得到。研究人员发现LIMA展现了强大的性能,并提出了表面对齐假设。文章还介绍了大语言模型的训练阶段和LIMA的训练方法。评估结果显示LIMA在满足提示要求方面表现良好。消融实验结果表明数据多样性对模型性能有显著影响。
完成下面两步后,将自动完成登录并继续当前操作。