
LIMA: Less Is More for Alignment 简读
原文中文,约2100字,阅读约需5分钟。
📝
内容提要
LIMA是一篇网红文,用SFT方案训练了一个模型,证实了表面对齐假设。该模型只用了1000条指令微调数据,但效果超过了使用52000条数据的Alpaca模型。LIMA验证了绝大部分的知识是在预训练阶段习得的,一定程度上也说明了有效的SFT甚至可以超越RLHF的结果。
🎯
关键要点
-
LIMA是一篇网红文,使用SFT方案训练模型,验证表面对齐假设。
-
该模型仅使用1000条指令微调数据,效果超过52000条数据的Alpaca模型。
-
LIMA证明大部分知识在预训练阶段习得,显示有效的SFT可超越RLHF结果。
-
LIMA的核心在于构建1000条多样性的指令数据,确保回复风格一致。
-
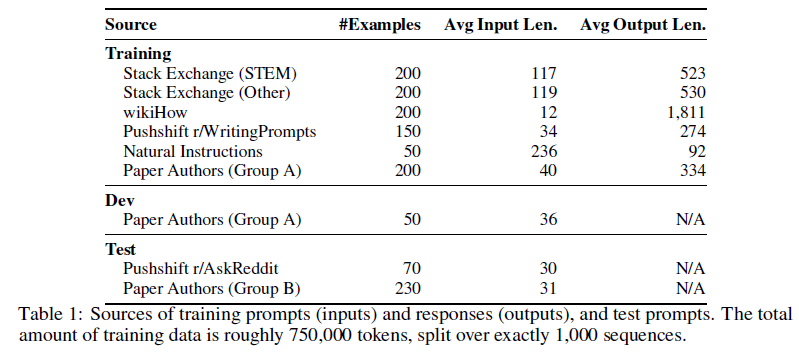
数据来源包括Stack Exchange、wikiHow和Pushshift Reddit,采用自动挖掘和手动改写相结合的方法。
-
Stack Exchange数据通过采样不同领域的问题和答案,过滤不合适的回复。
-
wikiHow数据通过采样高质量文章,确保多样性和一致性。
-
Reddit数据主要从r/AskReddit和r/WritingPrompts中选择高赞帖子,手动筛选。
-
作者手动编写示例以增加数据多样性,并从Natural Instruction数据集中选择任务。
-
LIMA模型基于LLaMa 65B进行微调,采用标准训练流程。
-
模型效果通过人工评估与OpenAI的DaVinci003和Alpaca模型比较,LIMA表现优越。
-
尽管BARD、Claude和GPT-4总体超越LIMA,但LIMA在许多情况下输出更好回复。
-
LIMA展示了高质量数据的重要性,但构建高质量数据集耗时耗力,难以扩展。
-
LIMA仍处于实验阶段,存在产生较差结果的可能性。
🏷️
