

数据工程师作为实时算法交易员 - 将数据管道转化为利润(或至少是尝试)!
DEV Community
·
![贪心-大模型微调实战营-应用篇[完结无密]](https://cdn.jsdelivr.net/gh/dqzboy/Blog-Image/BlogCourse/%E8%B4%AA%E5%BF%83-%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83%E5%AE%9E%E6%88%98%E8%90%A501.png)
贪心-大模型微调实战营-应用篇[完结无密]
浅时光博客
·

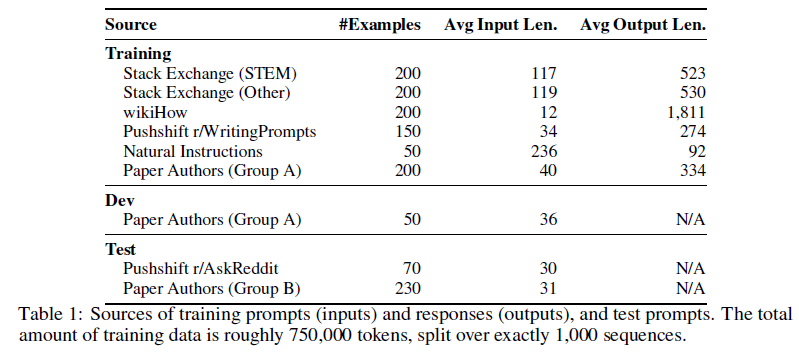
LIMA: Less Is More for Alignment 简读
Finisky Garden
·
Alpaca reappear
Kuricat's Blog
·

为啥大语言模型都跟羊驼干上了?
王建硕的博客
·
